


一键白标 Claude Code:自定义命令 + 启动画面 + 配置隔离,Skill可自取
一键白标 Claude Code:自定义命令 + 启动画面 + 配置隔离,Skill可自取这两天,我被一张图反复种草。
来自主题:
AI技术研报
8904 点击 2026-04-03 09:27
 搜索
搜索
这两天,我被一张图反复种草。
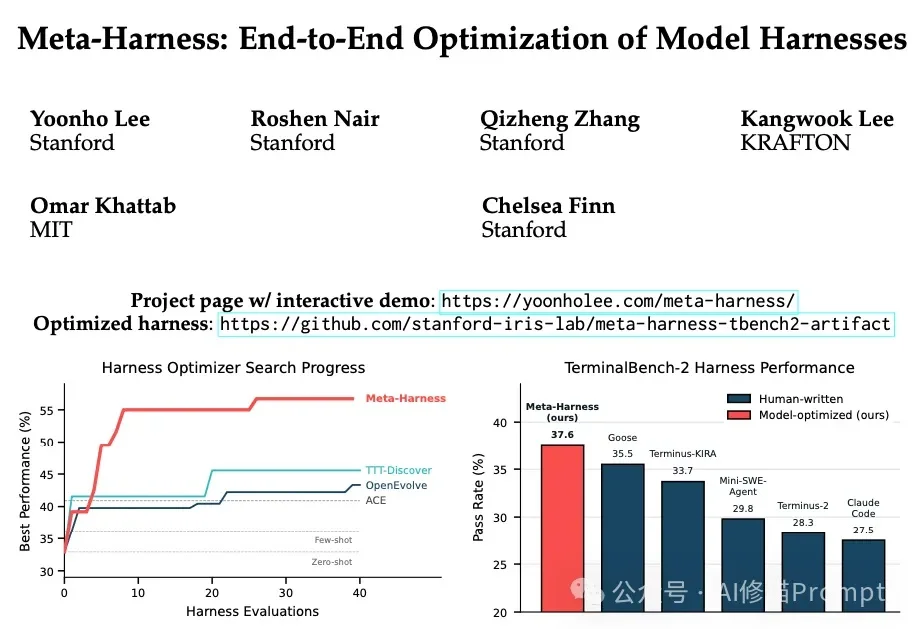
去年讨论Agent落地时,重点往往是Context Engineering。大家都在琢磨怎么放 Few-shot,怎么优化 RAG 检索的文本片段。但随着 Agent 任务复杂度的上升,控制数据流向、工具调度和异常处理的底层脚手架代码,往往比单纯拼接文本对系统性能的影响更大。

AI 能做翻译大家都知道,而且呢,AI 还会做一种更高级的翻译:中译中、英译英,简单来说,翻译空气。

3 月 31 日下午,技术圈炸了锅: Claude Code,这款被公认为当前最强的 AI 编程助手,因为一次内部失误,核心代码逻辑暴露在了全球开发者面前。
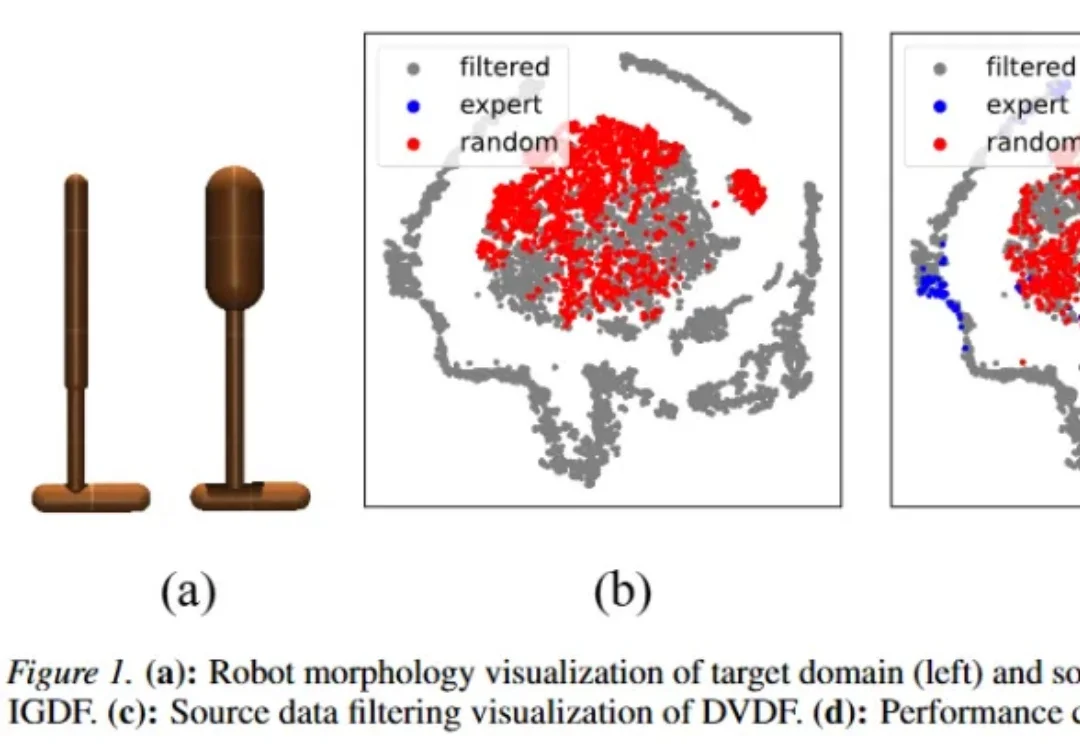
在现实世界中通过强化学习训练智能体,往往需要大量在线试错与环境探索,这不仅成本高昂,还可能带来显著安全风险:机器人可能因试错而损坏,自动驾驶的在线探索可能危及行车安全,而持续采集交互数据本身也代价巨大。
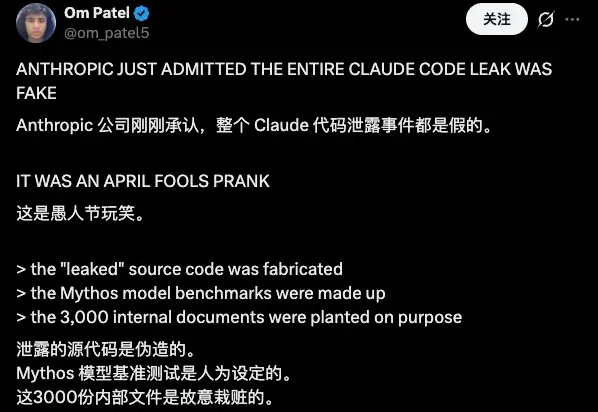
自从 30 号,Claude 传出最新的模型叫「卡皮巴拉」,愚人节的氛围就上来了。到后来 Claude Code 源码泄漏,更加是让互联网乱成一锅粥,赶紧喝了吧!
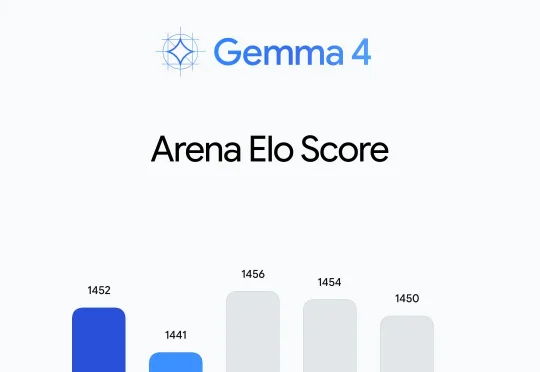
刚刚,谷歌正式发布 Gemma 4,称“这是其迄今为止最智能的开放模型系列”。该系列面向复杂推理与智能体工作流设计,采用商业许可的 Apache 2.0 许可证开源。Gemma 4 提供四种规格:Effective 2B(E2B)、Effective 4B(E4B)、26B 混合专家模型(MoE)和 31B 稠密模型(Dense)。
就在今天,消息人士爆出:Anthropic正在秘密测试核弹级产品——「永久在线」(Always-On)智能体Conway。也就是说,从此Claude将彻底「龙虾化」!
就在这个节骨眼上,我发现了一个非常有意思的东西,科大讯飞在 GitHub 上开源了一个叫 SkillHub 的项目。简单说,SkillHub 就是一个可以私有化部署的 Skill 技能包管理平台,团队可以在自己服务器上搭建,数据完全掌握在自己手上。

什么这code那code,先别code了,因为—— 中国最强编程模型来了!

昨天,OpenAI总裁Greg Brockman在Big Technology Podcast上,亲口透露了他们研究两年的重磅模型成果——Spud大模型。

最近,GitHub又炸出了一个明星项目:让「一个人开游戏公司」变成现实的Claude-Code-Game-Studios。与此同时,另一个「让普通人把想象变成游戏」的产品Aippy,也在欧美年轻人中风靡。与前者的专业工具属性不同,Aippy要做的是新一代数字原住民的「游戏社区」。

一场由斯坦福和普林斯顿联合发起的学术实验,正在挑战整个科研出版体系的底层逻辑。

据彭博社报道,OpenAI 的股票在二级市场上正在「失宠」。随着投资者迅速将资金转向其主要竞争对手 Anthropic,OpenAI 的部分股票在二级市场甚至变得难以出售。

字节也开始做“OpenClaw”了,但它先把战场放在了工作台上。

现在拿到的,还只是一张入场券,而不是比赛的结果。

今天,智谱正式发布 GLM-5V-Turbo。 看名字就知道,这次智谱新模型,视觉能力大大加强了!话不多说,这次小编直接开测,边测边为大家说一下对 GLM-5V-Turbo 的使用感受。

每天 120 万亿 Tokens,这就是今天上午火山引擎 AI 创新巡展上,豆包大模型亮出的最新成绩单。
在时间序列预测领域,深度模型如iTransformer、PatchTST虽然性能强劲,却长期困于“黑盒”困境——预测准,但说不出为什么。

104位开发者联手,全球最火开源AI助手OpenClaw再出重磅更新,第一次给AI Agent装上「操作系统」级的任务控制面板:让AI能够自己管理自己,会排任务也会说不:Agent竞赛的下半场来了。

生物医学AI智能体正从「能不能做组学分析」快速进入下一阶段的检验:做出来的结果,能不能撑得住真实的治疗决策?哈佛医学院Zitnik团队的MEDEA 给出了一条明确的技术路线:与其追求更强的骨干大模型,不如在分析流程的每一步嵌入验证机制。
近年来,Decision-Coupled World Model 与 Model-based RL 在机器人领域取得了显著成功。通过学习环境动力学模型,智能体能够在内部模拟未来,从而进行规划与决策。但当系统从单机器人扩展到多机器人时,问题开始变得棘手。

甲骨文凌晨突发裁员,不是愚人节玩笑。

谁能想到,OpenAI核心团队出来创业,竟被21家顶级VC拒之门外?结果5年后,这帮人为了抢一张入场券,不惜支付300倍溢价。复盘这场闹剧,我们只看到了一个词:活该!

硬氪获悉,运动AI Agent智能硬件品牌PathFinder Ltd.(以下简称“PathFinder”)近日完成数千万元天使轮融资,本轮由锦秋基金独家投资,资金将主要用于产品研发迭代、生产交付落地及早期渠道铺设,为后续众筹上线做好全面筹备。
《读佳》获悉,由北京青阳智维科技有限公司运营“量原求索Labelease”已推出,通过媒体报道可知,该公司隶属于字节跳动。 据悉,Labelease的主要作用是帮助模型团队解决模型从训练到部署全链路中

相似度超越Seed-TTS、MiniMax-Speech等知名模型。昨晚,美团LongCat团队发布了文本转语音模型LongCat-AudioDiT,并开源1B、3.5B参数量的版本。这一模型的最大特点,是彻底抛弃了梅尔谱等中间表示,直接在波形潜空间进行基于扩散模型的文本转语音。通俗地说,这一模型直接根据声音本身的规律进行生成,“雕刻”出最原始的声音波形,从根源阻断数据转换的级联误差。

大概一周前,我拿到了ColaOS(以下简称Cola)的内测。当时我手里有Claude、Gemini和GPT最新的模型。在Cola出现之前,这几个工具已经足够覆盖我所有的工作场景了。还有什么能比Claude好用?
今天,《人物》杂志发表了一篇报道: 「卧底」Kimi的100小时 文章中提到,Kimi 这群人,很会起名字,起名字的时候很有品味。 在 2025 年的 9 月,公司内部启动了一个小项目,名为「Enso
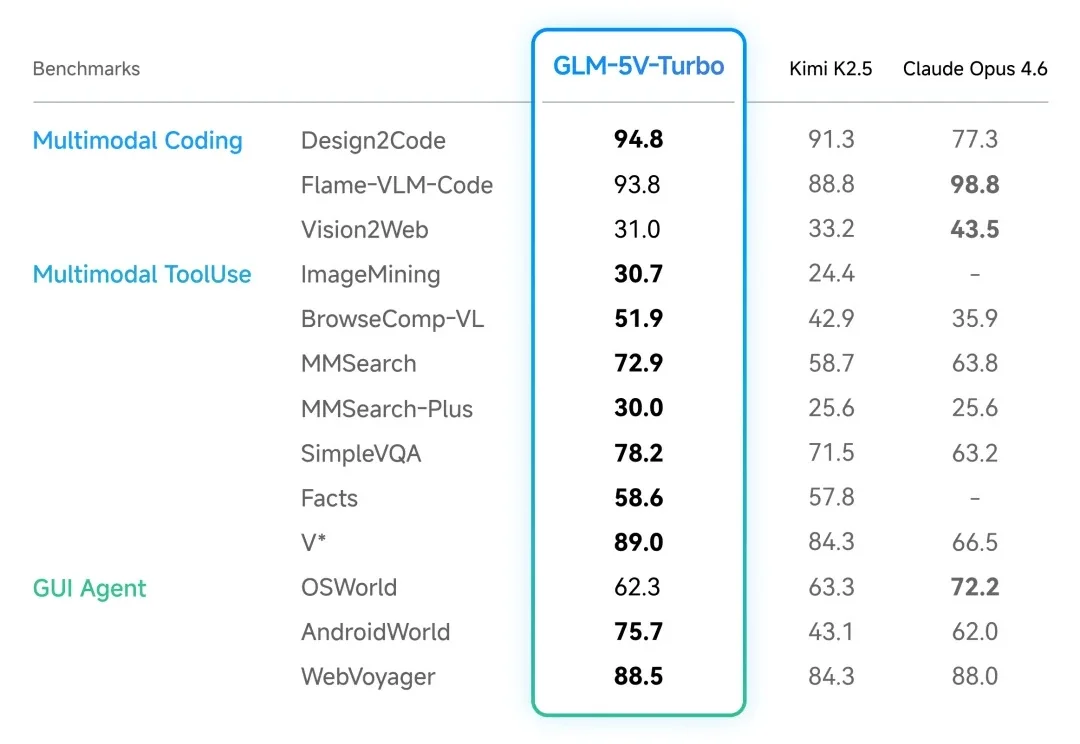
今天,智谱发布 GLM-5V-Turbo,定位「面向视觉编程的多模态 Coding 基座模型」。一句话概括:在 GLM-5-Turbo 的编程和龙虾能力基座上,加入了原生的视觉理解和推理能力

