


特斯拉被曝芯片被优先分配给AI公司,马斯克这样回应
特斯拉被曝芯片被优先分配给AI公司,马斯克这样回应媒体分析认为,英伟达的爆料可能会招致特斯拉股东对马斯克更严厉的批评。
来自主题:
AI资讯
9842 点击 2024-06-06 15:26
 搜索
搜索
媒体分析认为,英伟达的爆料可能会招致特斯拉股东对马斯克更严厉的批评。

事实证明,聊天机器人跟云端的其他服务一样容易出问题。

马斯克:到年底算力将拥有8.5万块H100
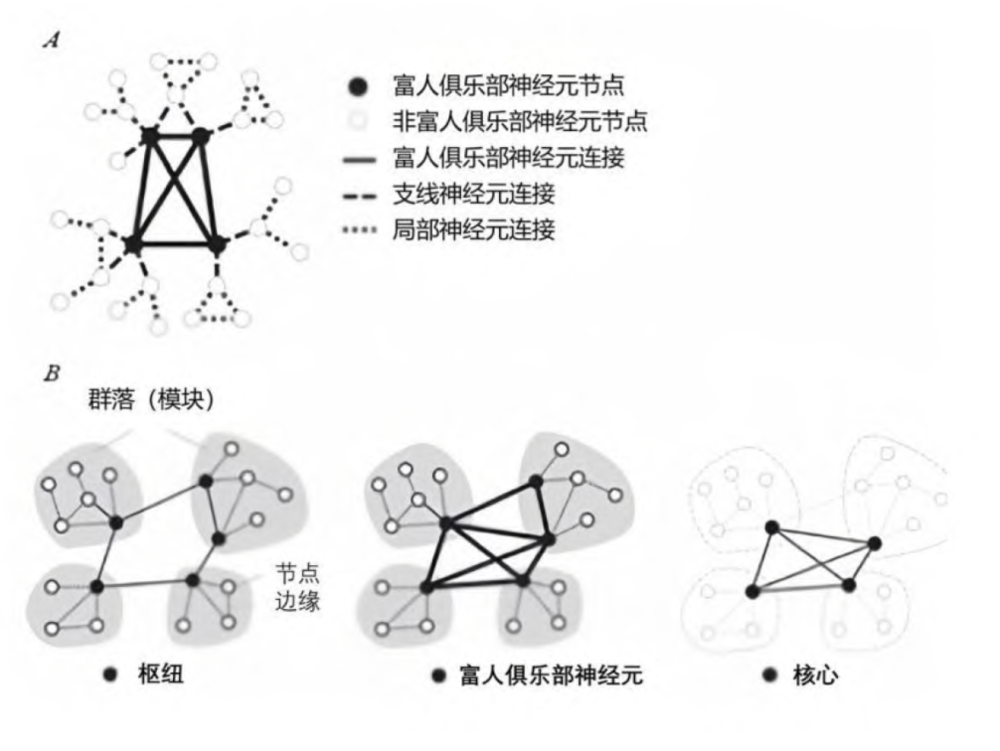
随着近年来人工智能(AI)的惊人进步,AI 是否具有意识以及如何构建有意识的 AI 系统越来越受到学界和公众的关注。要回答这类问题,我们仍然需要或者必须从意识理论中去寻找灵感和答案。

请想象这样一个场景。你坐在公交车上靠窗的位置,这时你的朋友突然对你说:“今天好像有点热”。你会怎么回应?大多数人的做法应该是立即打开窗户,因为他们巧妙地理解了朋友的言外之意:他是在礼貌地请求自己打开窗户,而不是单纯因为无聊而谈论天气。

天津大学与南京大学联合团队在CVPR 2024上发表了LPSNet项目,提出了一种端到端的无透镜成像下的3D人体姿态和形状估计框架,通过多尺度无透镜特征解码器和双头辅助监督机制,直接从编码后的无透镜成像数据中提取特征并提高姿态估计的准确度。

昨日,ChatGPT、Claude、Gemini和Perplexity四大聊天机器人同时宕机,引发网友竞相猜测。那么,在AI崩溃的几个小时里,对人类造成了什么影响?宕机又是如何发生的呢?

最近,OpenAI的一位前员工发表了一篇165页的超长博文,对AI发展的未来做出了一系列预测。文章的核心观点可以概括成一句话:人类很可能在2027年实现AGI。

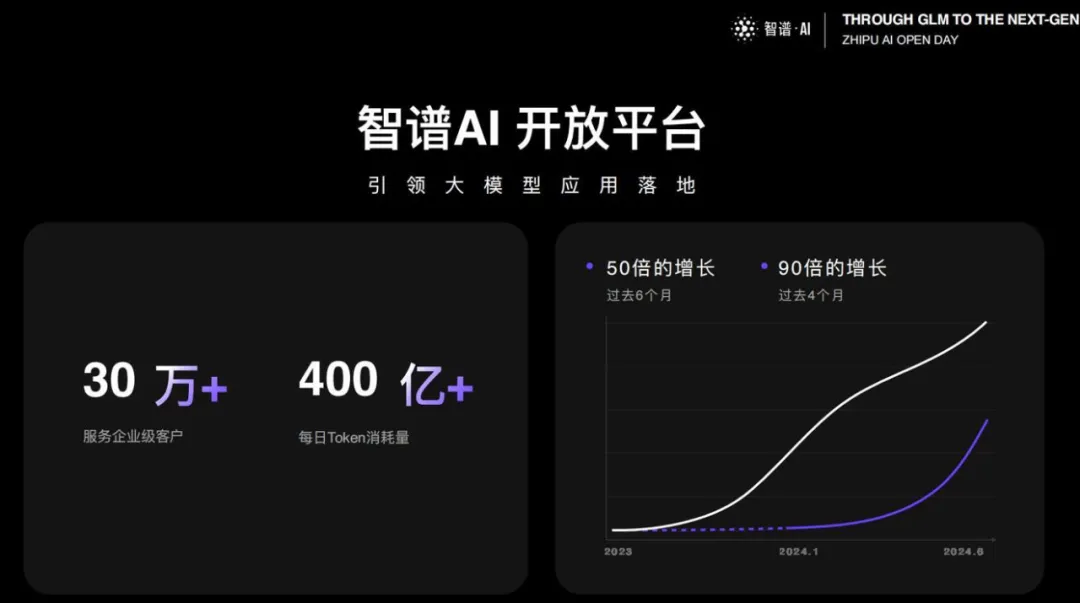
大模型价格战,这匹国产黑马又破纪录了!最低的GLM-4 Flash版本,百万token价格已经低至0.1元,可以说是击穿地心。MaaS 2.0大升级,让企业训练私有模型的成本无限降低。

Question.ai助力作业帮IPO背后,还有多款产品千里奔袭。

OpenAI CEO阿尔特曼的隐秘投资帝国浮出水面,持股价值超28亿美元,投资超400家公司。

AI,临床试验数字化企业必须抓住的下一个关键点

不卷参数,不卷价格,运营商只卷大模型的商业化落地。

十多位OpenAI员工联名吹哨:前沿AI公司会隐瞒风险,内部监管机制就是摆设!

由人工智能驱动的行业转型正在发生。

本文介绍了作者使用大模型进行AI校对书稿的经验和心得,包括使用AI校稿的初衷、与AI的合作过程以及对AI在校对后的稿件中的重要性的思考。 • ✨ 作者通过大模型进行AI校稿,提高了书稿的质量和效率 • ???? 作者强调人类与AI的合作,强调人类的思考价值和责任 • ???? 通过详细的提示词和沟通方式,作者实现了与AI的有效合作,提高了书稿质量

本文介绍了KAN网络算法的原理和优势,探讨了其在深度学习领域可能引发的范式转变。 • ⚡ KAN网络将可学习的激活函数从神经元移到了神经网络的边上,表现出更高的准确性和更少的参数量 • ???? KAN在数学和物理领域的实验中展现了卓越性能,提供了一种新的科学发现的路径 • ???? KAN具有更快的神经缩放定律和可解释性,为AI领域带来了新的探索可能性

衔远科技的经历,只是国产大模型军备竞赛的冰山一角。
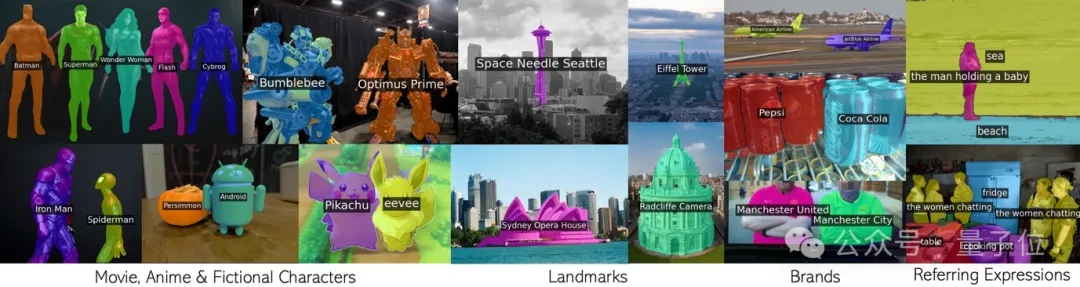
循环调用CLIP,无需额外训练就有效分割无数概念。 包括电影动漫人物,地标,品牌,和普通类别在内的任意短语。

北航的研究团队,用扩散模型“复刻”了一个地球? 在全球的任意位置,模型都能生成多种分辨率的遥感图像,创造出丰富多样的“平行场景”。 而且地形、气候、植被等复杂的地理特征,也全都考虑到了。

英特尔为了AI,再次做出重大架构变革: 像手机一样搞起SoC(系统级芯片),你的下一台笔记本不会再有独立内存条。 刚刚推出的新一代AI PC低功耗移动平台架构Lunar Lake,采用全新MoP(Memory on Package)封装,片上集成16或32GB的LPDDR5X内存,无法再额外连接更多RAM。

一个年仅9岁的男孩,利用AI智能体,竟然出版了一本书!

过去十年间,基于随机梯度下降(SGD)的深度学习模型在许多领域都取得了极大的成功。与此同时各式各样的 SGD 替代品也如雨后春笋般涌现。在这些众多替代品中,Adam 及其变种最受追捧。无论是 SGD,还是 Adam,亦或是其他优化器,最核心的超参数非 Learning rate 莫属。因此如何调整好 Leanring rate 是炼丹师们从一开始就必学的技能。
实时游戏内的指导和分析,助力你的上分路。
最新版本大模型,6 分钱 100 万 Token。

大模型出现以来,整个行业的资金循环模式是什么样子呢?投资注入大模型公司,大模型公司买卡注入英伟达。这正是过去十年间AI典型的非良性循环,但与上次不同的是,这次确实正在一点点摆脱此前十几年间的惯性。现在我们处在什么位置呢?水温80度,正是一个要开还没开的节点。
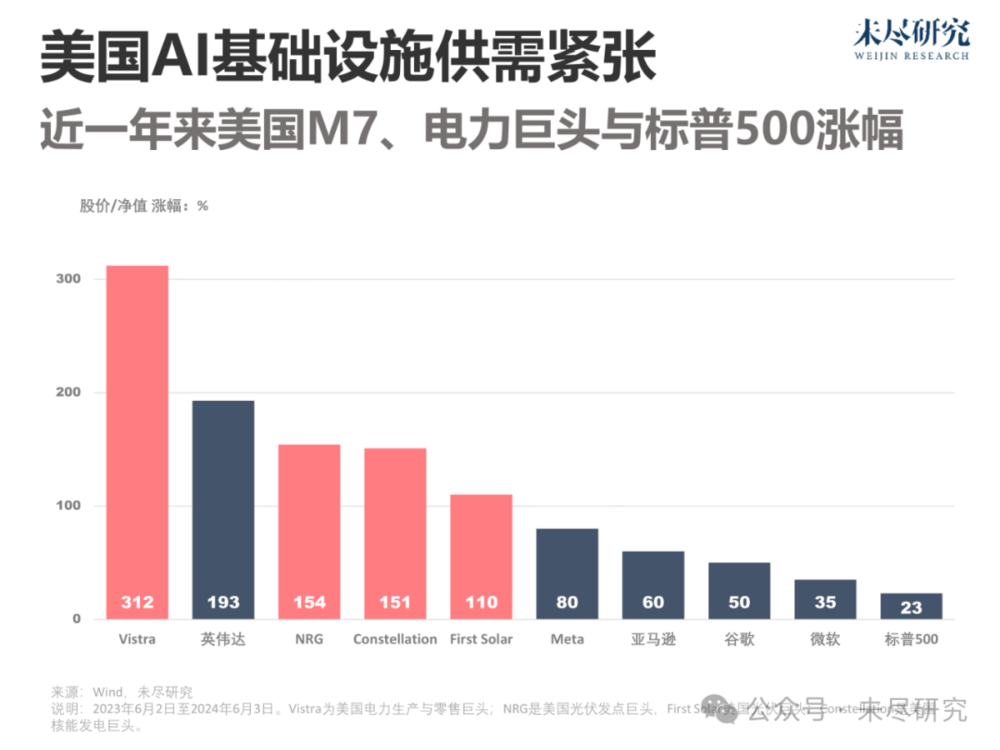
美国电力巨头们的股价正在因为AI而疯狂,近一年来涨幅普遍翻番,甚至超过了英伟达。正在建设AI基础设施的七大科技巨头(M7)们,不仅抢着向英伟达要货,还在抓紧和这些电力巨头们签订合同。也难怪黄仁勋前两天在COMPUTEX的演讲中频繁强调芯片能耗。中国人工智能要追赶美国,会遭遇类似的“电力危机”吗?

大模型退潮,多家明星公司“卖身”

AI检测AI。

淘宝跳转拼多多式的难题

