

9秒,公司没了!Claude「删库跑路」,Anthropic封杀110人公司,却还在扣钱
9秒,公司没了!Claude「删库跑路」,Anthropic封杀110人公司,却还在扣钱一家110人的农业科技公司,周一早上集体发现Claude账号全部被封。没有预警,没有解释,API还在照常计费。申诉36小时,石沉大海。企业把命押在一个AI上,这就是代价。
来自主题:
AI资讯
9391 点击 2026-04-28 15:09
 搜索
搜索
一家110人的农业科技公司,周一早上集体发现Claude账号全部被封。没有预警,没有解释,API还在照常计费。申诉36小时,石沉大海。企业把命押在一个AI上,这就是代价。
黄仁勋说Agent将创造100万亿美元。易鑫用Model+Harness的硬核组合,把这一预言提前落地汽车金融,效率革命已悄然拉开帷幕。
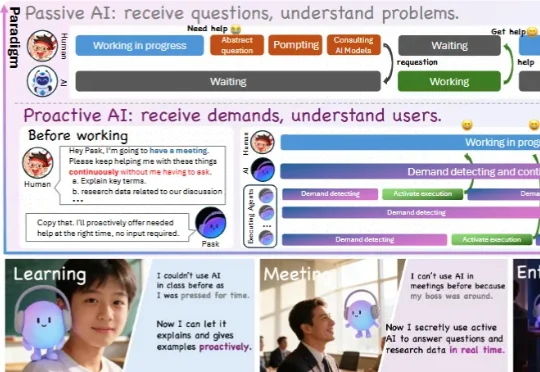
让AI像助手一样主动帮助,才是我们心中AGI的样子。主动智能体的概念已经被多次提出,但都很难做到可以真正在生活中落地。现有的工作都还停留在概念层面,无法解决复杂世界中所要求的实时性、深度、和记忆等问题。 南洋理工大学谢之非团队提出Pask,使用「底层小模型流式意图检测」+ 「上层Agents执行」架构,实现首个能够做到实时、有深度、基于个人全局记忆自进化的主动智能体。

2026 年初,浙江大学发表了一篇系统性的 SoK 论文《Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward》,给Skill下了一个正式定义。
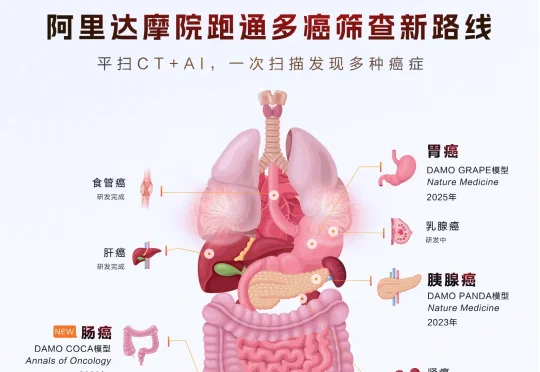
医生说平扫CT上看不见癌——AI找到了。 2021年5月,一位患者因突发腹痛被推进急诊,拍了一张平扫CT。 影像报告出来了——没有提及肠道有问题。 两年后,这位患者做了肠镜。确诊肠癌。肿瘤已经明显增大
Shade 完成了 1400 万美元 融资。本轮由 Khosla Ventures、Construct Capital 与 Bling Capital 共同领投,公司累计融资达到 2000 万美元。如果只看功能,这是一个支持自然语言搜索视频素材的存储工具;但从更底层来看,它试图重写的是一个更基础的前提——内容在组织内部是如何存在、被理解以及被再次使用的。

你有没有想过,不用联网、仅用一张消费级显卡,就能在个人电脑上拥有一个「边看、边听、边说、还能主动提醒」的类人 AI 助手?这就是 MiniCPM-o 4.5 所能做到的。在技术创新下,它仅凭 9B 参数,实现了业界首个端到端全双工全模态大模型,让端侧 AI 普惠成为现实。其自 2026 年 2 月模型发布以来,在 Hugging Face 上的下载量已突破 25 万+。
一个开发者公开了自己的工作流:让 OpenAI Codex 专门去审查 Hermes agent 写出来的代码,理由只有一个——审稿人不能和写稿人共享同一套记忆。这条推文引发了近万次浏览,背后藏着一个 agent 工程化的新趋势:多模型协作的价值,可能在于互相制衡。
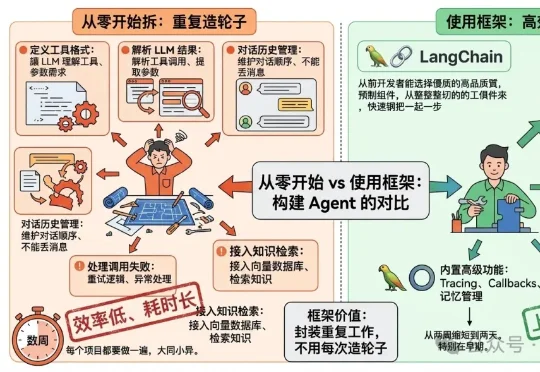
我的感受是框架用起来快,但有几个实际痛点。第一是抽象层太多,调试的时候不知道哪步出了问题,得一层层往下扒;第二是版本升级经常有破坏性变更,线上稳定性难保证;第三是框架的通用设计往往和具体业务需求有偏差,定制起来反而更费劲。手搓的代码完全在自己掌控之内,可观测性好、出问题好排查,也更方便做性能优化。所以我现在的策略是核心逻辑手写,只在边缘功能上用框架的工具。
《读佳》独家获知,腾讯悄悄内测一款叫做“马维斯Marvis”的AI产品,可能是国内首个真正“接管电脑”的AI助手,产品除了桌面版外,还有APP版本。眼下AI圈正流行“养马”(Hermes)“养虾”(OpenClaw)热潮,而腾讯内测的Marvis,聚焦PC场景,做更落地、更懂系统的“桌面AI管家”。以下为其展示的页面功能及内容,仅供参考:

4月27日,监管依法禁止美国科技巨头Meta收购中国AI企业Manus,并要求撤销该交易。对Manus来说,最直接的冲击就是20亿美元的交易泡汤了,管理层、核心员工、投资人等也失去了一个“绝佳”的退出机会。
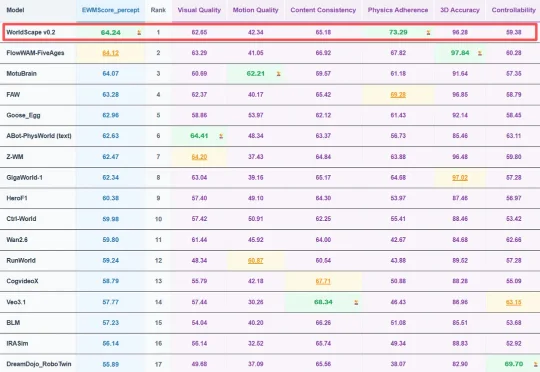
近日,全球具身世界模型权威基准评测 WorldArena 正式更新最新榜单。Manifold AI 流形空间研发的世界模型 WorldScape 0.2,凭借其在物理规律遵循与多源交互理解上的突破取得 WorldArena 榜单全球第一,充分展现了国产世界模型在复杂动态场景生成与具身控制中的高精度、强泛化与物理可信度。与其同场竞技的包括英伟达、谷歌等国外巨头和星动纪元、极佳视界等国内具身智能公司。

在真正熟悉3D高斯泼溅技术的圈子里,“大规模3D高斯模型在移动端打开” 的技术早已不是什么新鲜事。两年前就有一家深圳创业公司,做出来并推出完整产品,甚至开源至GitHub。
毕竟,这个工具在我看来,他目前确实不仅是Claude Code里接国产模型,也还是其他的各种Agent产品比如OpenClaw、Hermes等等里面,切换模型最方便、最好用的一个。他就是开源的大名鼎鼎的cc switch,至今在github上已经50k的星标了。

Voice Working来了!TRAE SOLO把「说话」变成主力干活方式,口语自动清洗、说错自动纠正、一句话调Skill切模式。动动嘴就能指挥你的电脑干活了!
刚刚,小米开源罗福莉带队研发的MiMo-V2.5系列模型,采用MIT协议,允许商用推理部署与二次训练,无需额外授权。此前,该系列模型于4月23日开启公测,包括MiMo-V2.5-Pro、MiMo-V2.5两款模型。模型具备更强Agent能力,支持100万上下文,且Token效率大幅提升。

2026 年的 AI 行业不断加速,仿佛只有一个正确答案:卷 Agent,卷效率,卷生产力。跑得慢的人都在补课,跑得快的人已经在找下一个风口了。但在京东 JoyInside 首届「AI 终端新物种」硬件创新大赛的现场,几个与提升效率完全无关的产品,却让我十分好奇。

今天凌晨,微软与OpenAI联合宣布,修订延续多年的合作协议,结束了微软在OpenAI模型对外分销上的独家地位,OpenAI从此可向所有云服务商客户提供其全部产品。微软将不再向OpenAI支付收入分成,OpenAI对微软的收入分成持续到2030年,并设总额上限。

4月27日,小红书首次公布AI治理主张:AI让创作变得更高效,也让造假变得更容易。仿冒真人、批量刷内容、侵占他人原创——这些行为消耗的,是每一个认真做内容的人换来的社区信任。

AI行业最刺眼的新成本,正在从GPU变成保镖。奥特曼住宅外的燃烧瓶、老黄身后的安保队伍、特朗普晚宴的枪声,指向同一件事:AI不再只是产品和股价,也开始变成现实世界里的情绪靶心。
今日,蚂蚁灵光App上线“体验世界模型”功能,成为业界首个可在移动端体验世界模型的智能助手,实现了分钟级一致性和实时可交互体验。用户只需上传一张图片,即可在手机上探索最长60秒的3D世界,并通过手游摇杆操控视角,像玩游戏一样在其中走动。从触发指令到开始探索,整个过程仅需秒级。

两天前,Creati AI推出了新产品Buzzy。Buzzy是一个专门做视频修改的AI Agent。用户可以对视频说“把这个人换成我的脸”“把阴天变成黄昏”“去掉背景里的路人”,局部修改,其他不动。几乎同时,公司官宣了由红点领投的B轮融资,金额高达2000万美元。

SentiPulse(思维光谱)公测了一款叫 SentiCat 的产品,把这套理念落了地。一个有 Live2D 形象、有性格的数字角色 SUSU,负责陪你聊天、了解你、跟你建立关系;她的“AI 小猫”,负责写 PPT、查资料、改代码,脏活累活归它。

橘子在采访中说了一句话,我们决定把它作为这篇文章的结尾: “大家在一起见证一个伟大的超级智能系统的诞生。而每一个人的灵魂,最终都会让这个东西变成可能。”

MoE模型的稀疏激活本是优势,却常陷通信瓶颈。NVIDIA以软件为利剑,通过程序化依赖启动和全对全通信革新,在三个月内将GB200的单GPU吞吐提升2.8倍,真正释放Blackwell硬件潜力。
Harness(驯马)会成为这个(AI)时代最关键的能力之一。这是小马智行CTO楼天城,在与量子位的对话中,给出的最新判断。在他看来,如今的AI越来越像一匹脱缰野马。它开始学会了「调用」:调用工具、调用skills……因此能通过这些脚手架,自我演进,和人类打配合。

腾讯混元团队提出了 Multi-Stream Scene Script(MTSS),一种全新的视频描述范式 —— 将传统的 "一段话描述整个视频" 升级为 "多流结构化剧本",通过 Stream Factorization 和 Relational Grounding 两大核心原则,让视频描述既忠实又可扩展,在视频理解和生成任务中均取得显著提升。

4月27日消息,智能纪元AGI独家获悉,阿里云和美团联合创始人王慧文投资的AI Infra公司硅基流动联合创始人、增长业务副总裁杨攀近期从硅基流动离职,正考虑再次创业。

4月27日,Manus和Meta那笔传了几个月的交易,终于等来了最终结果。不是“继续审查”。不是“补充材料”。而是禁止投资,要求撤销交易。这几个字很重。

今天,阿里ATH创新事业部的最新视频生成与编辑模型HappyHorse 1.0(官方译名:快乐小马)开启灰度测试。创作者可在阿里云百炼平台和HappyHorse官网注册使用,大众用户可在千问App中体验。

