


小米成立AI平台部,张铎任负责人
小米成立AI平台部,张铎任负责人雷军钦点的小米技术大神,回来了。
来自主题:
AI资讯
9550 点击 2024-11-14 21:38
 搜索
搜索
雷军钦点的小米技术大神,回来了。
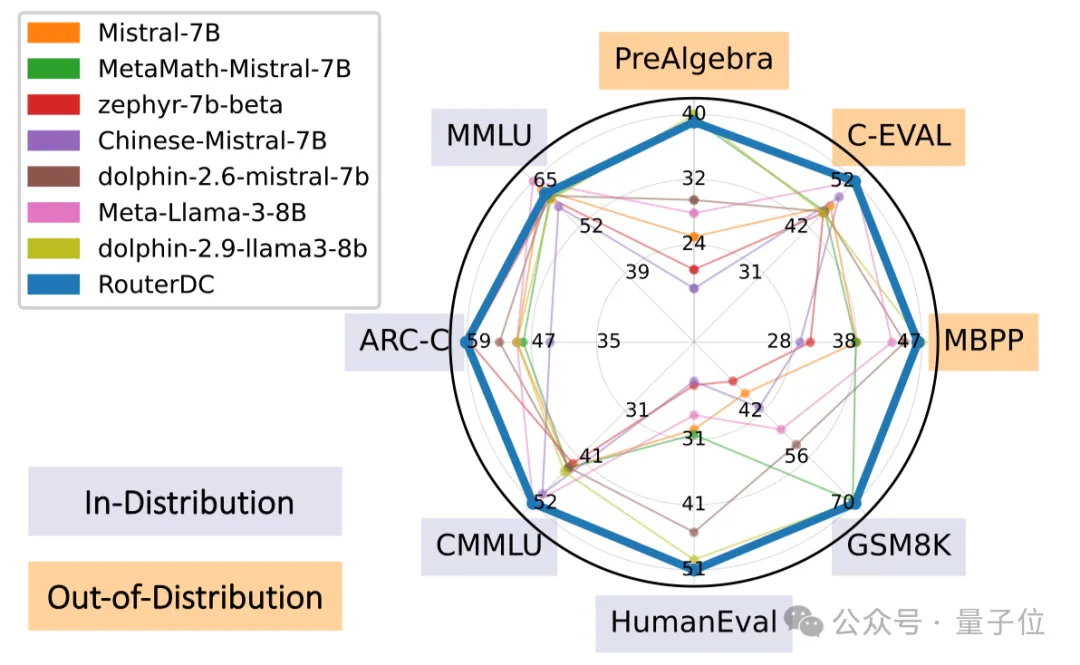
高效组合多个大模型“取长补短”新思路,被顶会NeurIPS 2024接收。
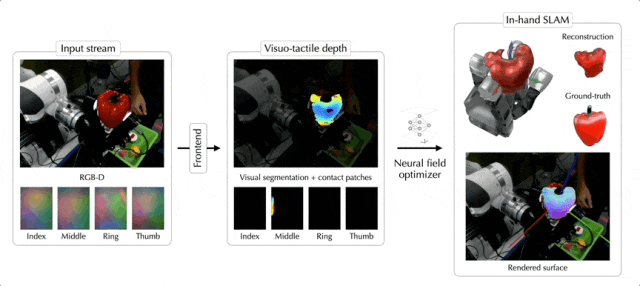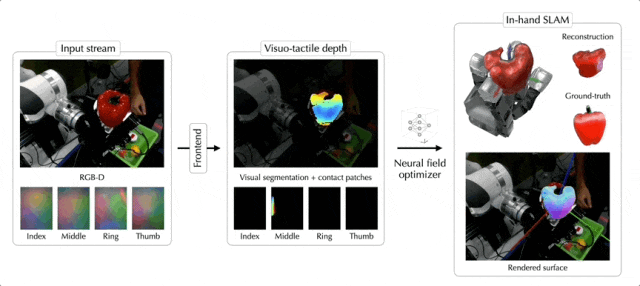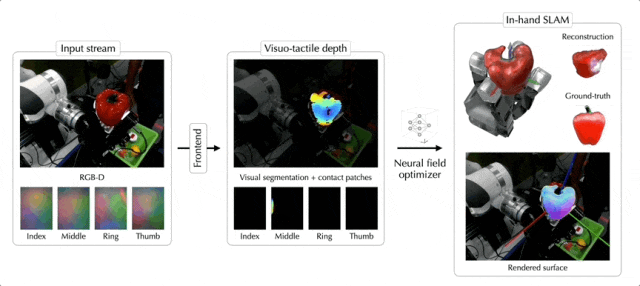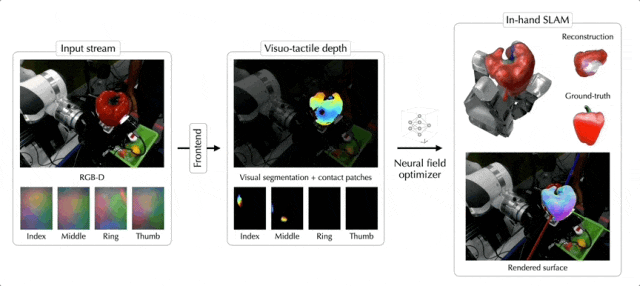
现在,随便丢给机械手一个陌生物体,它都可以像人类一样轻松拿捏了——
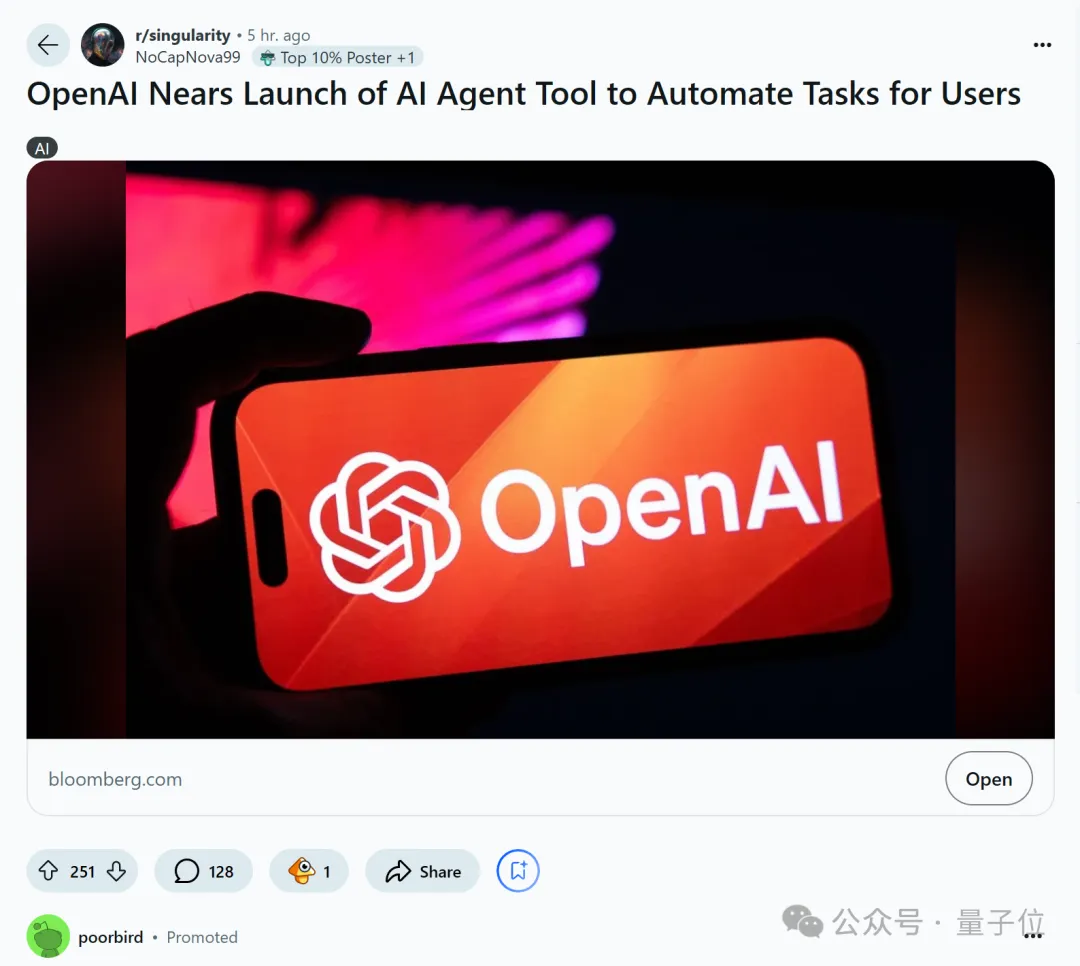
继Anthropic之后,OpenAI也要接管人类电脑了?!
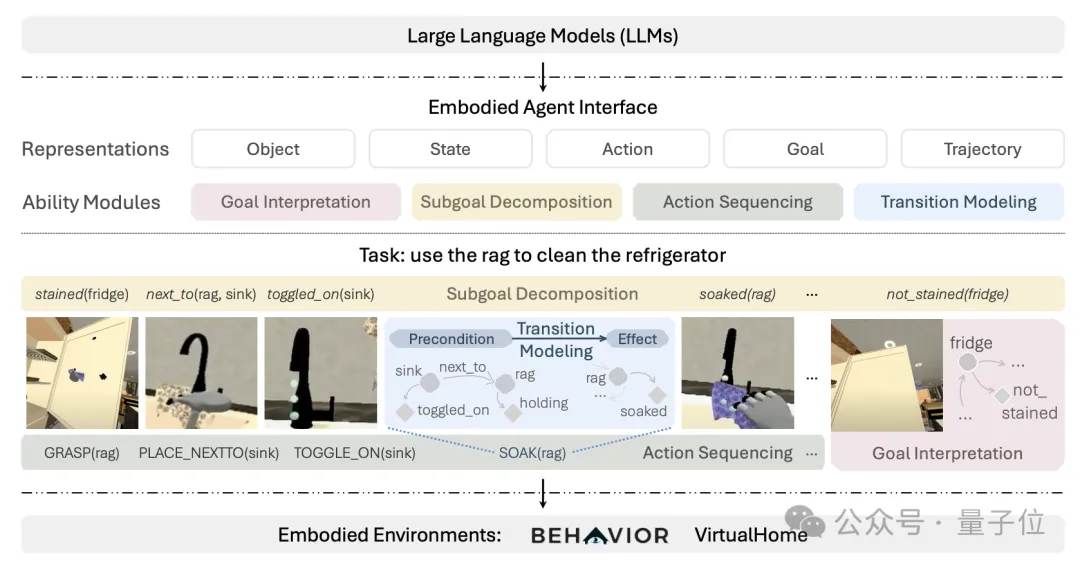
大模型的具身智能决策能力,终于有系统的通用评估基准了。

大模型的发展呈现出追风逐日般的速度,但与之相伴的安全问题,也是频频被曝光。

继 OpenAI o1 成为首个达到 Kaggle 特级大师的人工智能(AI)模型后,另一个 Kaggle 大师级 AI 也诞生了。

刚刚,谷歌官方宣布了一条重磅消息: Keras之父François Chollet,正式离职。

三张图攒一个毫无违和感的视频!

在硅星人首届AI创造者大会(ACC 2024)上,五位AI Agent领域的先行者展开了一场关于技术落地与商业化的深度对话。来也科技联合创始人胡一川、实在智能创始人&CEO孙林君、汇智智能创始人&CEO孙志明、澜码科技创始人&CEO周健,以及主持人、AI创业者李博杰共同探讨了一个核心问题:AI Agent如何从学术概念真正转变为驱动企业增长的工具?

36氪获悉,近期,欧洲虚拟电厂企业Green Voltis宣布成功完成天使轮融资,金额近千万美元。本轮融资由创世伙伴领投,云启资本、九合创投共同参与。此次融资将主要用于AI Native虚拟电厂的技术创新和市场拓展。

今日凌晨,Stability AI 发布了 Stable Diffusion 3.5 的提示指南。该指南提供了 Stable Diffusion 3.5 的实用提示技巧,让使用者能够快速准确地完善图像概念,更好地使用 Stable Diffusion 3.5 这一在可定制性、高效性能、多样化输出和多功能风格方面均表现出色的模型。

OpenAI治理研究员Richard Ngo宣布离职。近来,OpenAI中专注于AI安全的员工接连出走,Ngo是最新的一位。

本期我们邀请到了 Hedra 的联合创始人兼 CEO Michael。他曾在斯坦福大学攻读博士学位,由吴教授和李飞飞教授共同指导,专注于物理世界建模与具身智能的交叉研究。在 NVIDIA 的 Omniverse 团队实习期间,他参与了 Omni-Gibson 的研究,对模拟物理与真实感表现系统的结合有深入探索,同时对电影、电视剧和动画等娱乐行业充满热情。

AI 驱动的搜索引擎 Perplexity 表示,它将从本周开始在其平台上进行广告实验。

大模型狂热继续,但今天依然沿着一条路或者一个路线图前进的公司或产品却并不多了,有的“模型”公司做着做着没模型了,有的从情感到生产力再到视觉做了个遍,有的干脆从c转到b,也不再批评过往b端必做的项目制了。

传统的训练方法通常依赖于大量人工标注的数据和外部奖励模型,这些方法往往受到成本、质量控制和泛化能力的限制。因此,如何减少对人工标注的依赖,并提高模型在复杂推理任务中的表现,成为了当前的主要挑战之一。

Recraft团队通过结合TextDiffuser-2技术和自训练的大型语言模型,提升了文本到图像渲染的质量和准确性,不过现有模型在处理复杂语言如中文和未明确指定的文本时,仍存在渲染不准确的问题。

全球首个支持多主体一致性的多模态模型,刚刚诞生!Vidu 1.5一上线,全网网友都震惊了:LLM独有的上下文学习优势,视觉模型居然也有了。

随着人形机器人技术的迅猛发展,如何有效获取高质量的操作数据成为核心挑战。鉴于人类操作行为的复杂性和多样性,如何从真实世界中精准捕捉手与物体交互的完整状态,成为推动人形机器人操作技能学习的关键所在。

五年内 AGI 还能否如期而至?
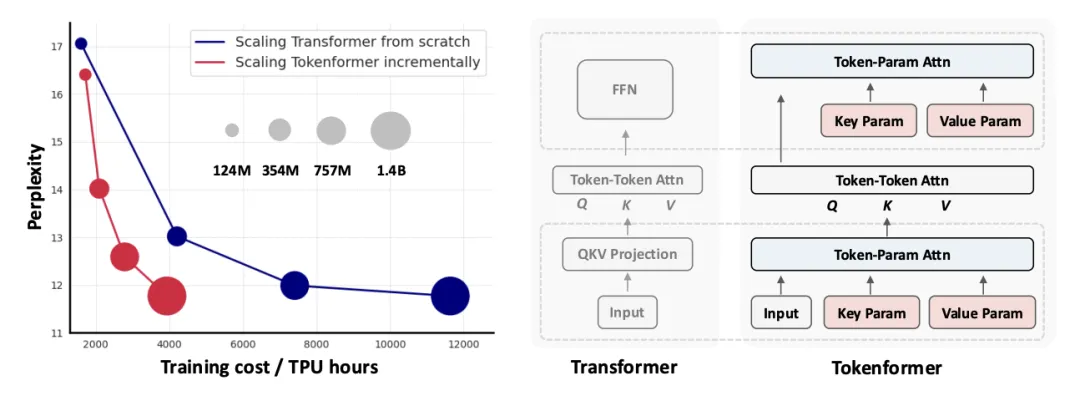
新一代通用灵活的网络结构 TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters 来啦!

在未来,得AI者才能得天下。 今年年初,OpenAI发布了“文生视频”的工具Sora,仅凭几段视频,就让很多人见识到了AI生成视频的力量。

随着大语言模型(LLMs)在处理复杂任务中的广泛应用,高质量数据的获取变得尤为关键。为了确保模型能够准确理解并执行用户指令,模型必须依赖大量真实且多样化的数据进行后训练。然而,获取此类数据往往伴随着高昂的成本和数据稀缺性。因此,如何有效生成能够反映现实需求的高质量合成数据,成为了当前亟需解决的核心挑战。

彭博今天消息,OpenAI 正准备推出一款代号为“Operator”的全新AI Agent产品,可以自动执行各种复杂操作,包括编写代码、预订旅行、自动电商购物等。

不瞒大家说, AI 已经全面融入差评了。
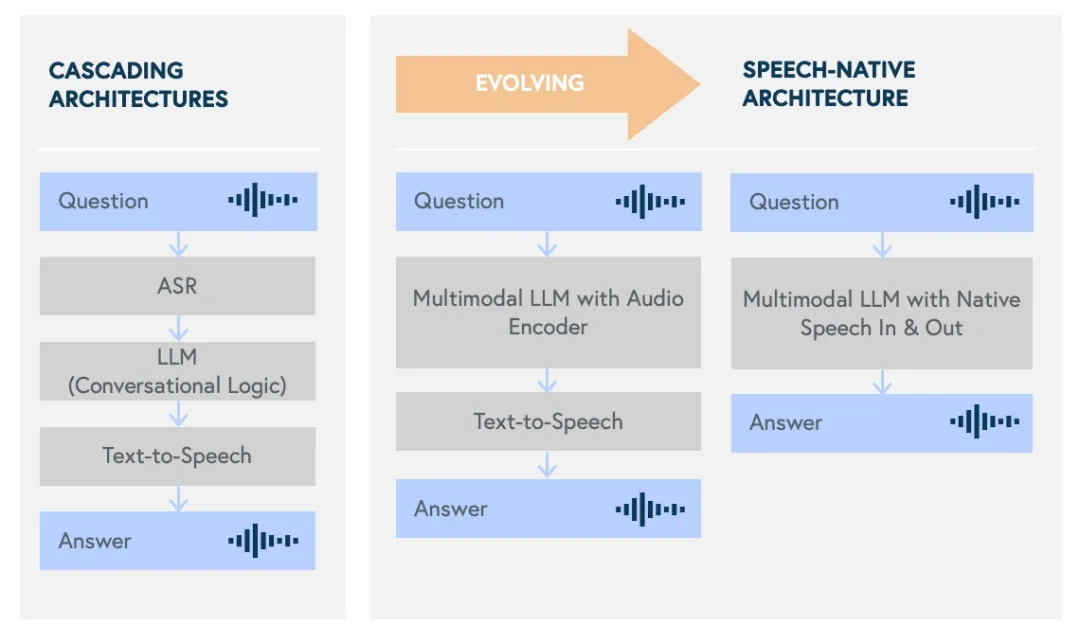
「未来,消费者更可能倾向于与 AI 沟通,而非人工客服,因为这将成为解决问题的最高效途径。」

30多年的数学猜想首次获得了进展!Meta等学者提出的PatternBoost,使用Transformer构造了一个反例,反驳了一个已悬而未决30年的猜想。是否所有数学问题都适合机器学习技术?这样的未来太令人期待了。

随着云计算平台的搭建和数据量的爆炸式增长,生成式人工智能(AI)在艺术领域的应用变得日益广泛,在多种技术交织而成的新型创作语境中,文艺创作迎来了新的挑战和机遇,AI技术正在重塑影视工业的全流程,并为观众带来前所未有的视听体验。

手机厂商VS超级APP,巨头逐鹿AI时代

