

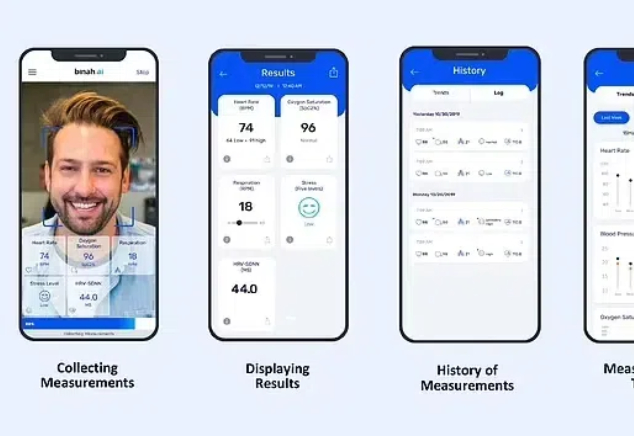
AI版周扒皮!打字速度慢、鼠标超30秒未动,就被AI「警告」,Karpathy下场评论
AI版周扒皮!打字速度慢、鼠标超30秒未动,就被AI「警告」,Karpathy下场评论「带薪拉屎」越来越难,求摸鱼技巧更新!
来自主题:
AI资讯
9153 点击 2024-11-24 20:57
 搜索
搜索
「带薪拉屎」越来越难,求摸鱼技巧更新!
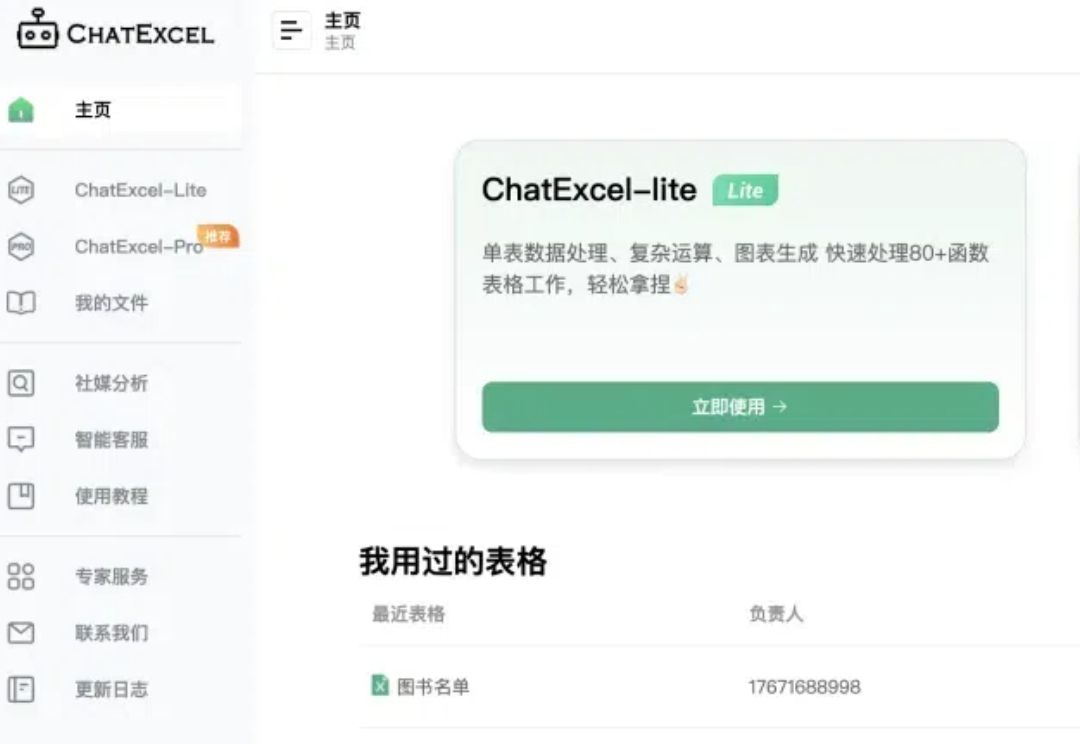
AI做Excel表,现在next level了—— 北大团队ChatExcel最新升级,一句话搞定线性分析,图表、文字总结全都有。
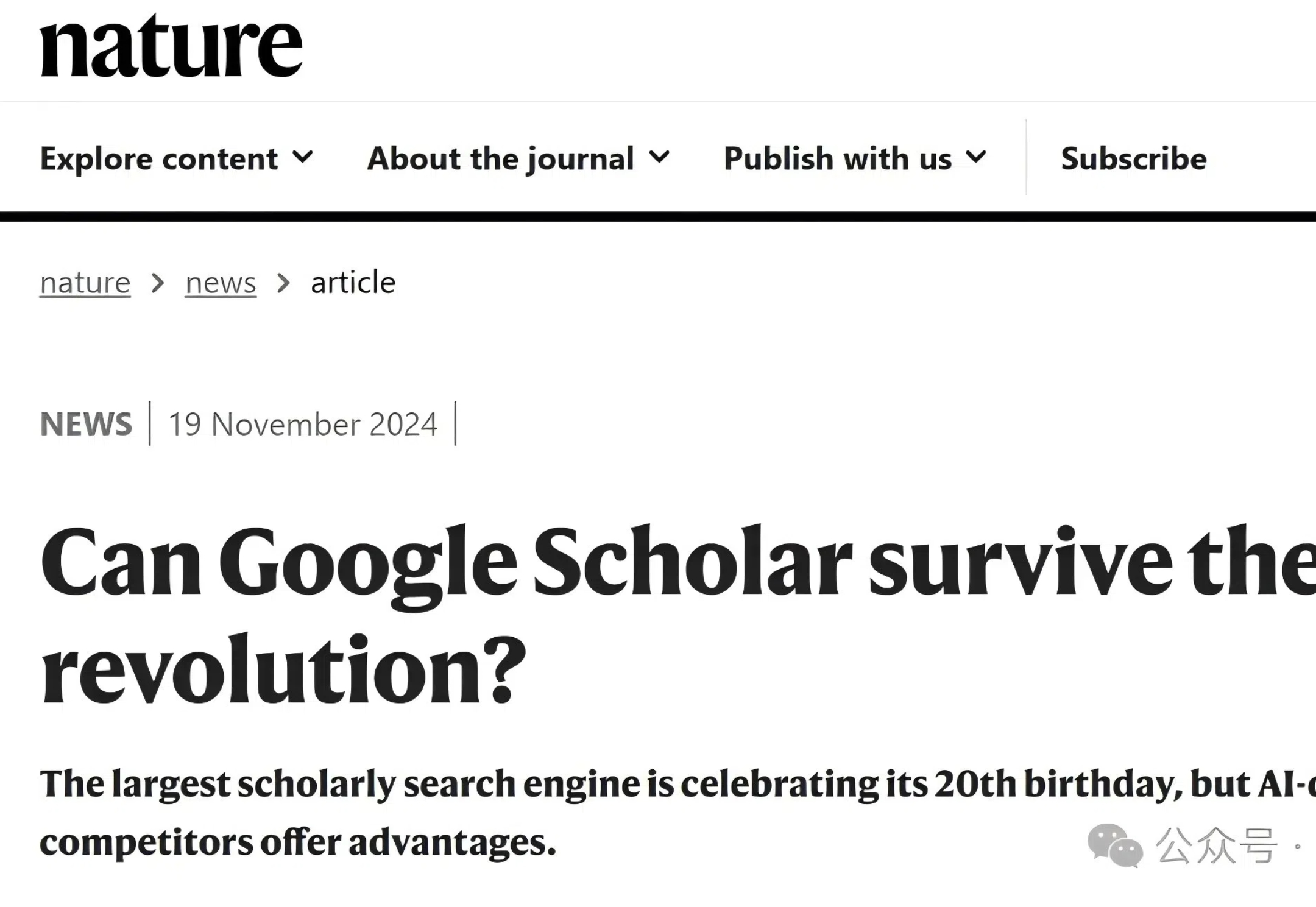
曾经每天都用谷歌学术的科学家们,正在转向新的AI工具。

Meta的视频版分割一切——Segment Anything Model 2(SAM 2),又火了一把。

扩散模型的本质竟是进化算法!生物学大佬从数学的角度证实了这个结论,并结合扩散模型创建了全新的进化算法。
这个周末,押注开源人工智能视频的初创公司 Lightricks,有了重大动作。 该公司推出了最快的视频生成模型 LTX-Video,它是首个可以实时生成高质量视频的 DiT 视频生成模型。
我们对小型语言模型的增强方法、已存在的小模型、应用、与 LLMs 的协作、以及可信赖性方面进行了详细调查。
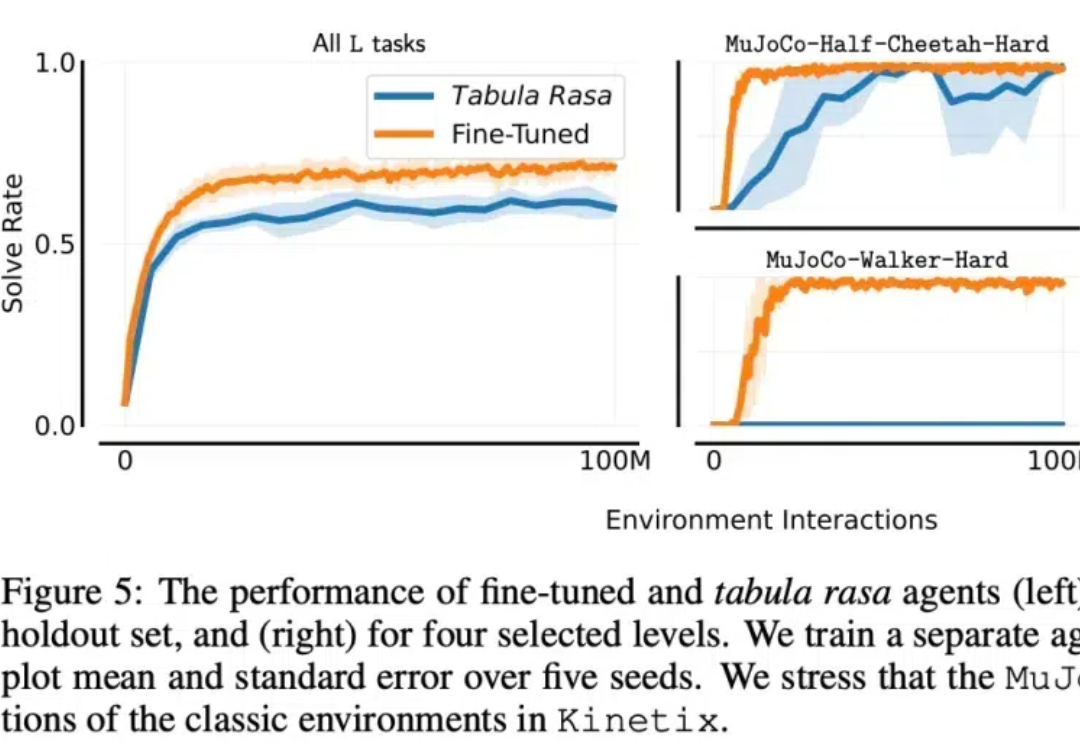
在机器学习领域,开发一个在未见过领域表现出色的通用智能体一直是长期目标之一。一种观点认为,在大量离线文本和视频数据上训练的大型 transformer 最终可以实现这一目标。

Jiaming Song详细介绍了Diffusion模型在视觉生成领域的前沿研究,强调其在提升生成视觉模型质量中的关键作用。他分享了自己从斯坦福大学的博士研究到加入NVIDIA和Luma AI的历程,展示了如何将贝叶斯非参数模型的知识应用到生成式AI中,推动了视觉模型在生成质量和速度上的显著提升。
作为一个专业的程序员,我想给 AI 编程这个话题祛祛魅,通过实际的应用场景,分享 AI 辅助编程如何提升日常工作效率 / AI 编程的能力边界在哪里 / 我们应该如何用好 AI 辅助编程工具。
AI coding copilots迅速融入开发流程,提升开发效率,协作是未来趋势,开发者与AI将共同推动编程的变革。

“这是地球上最好的域名。”——马斯克如此评价x.com。2017年,他花费500万美元从paypal手中重新买回x.com,后来他买下的社交媒体平台Twitter更名重塑为X。

在11月20日盘后,英伟达(NVDA.O)公布的财报显示,第三季度营收达到351亿美元,增幅近乎翻倍。

截至目前,小红书已在大模型、AI 对话、AI 搜索、AI 绘图等 4 个领域进行了布局。陆续上线了 6 款产品,主要围绕搜索和创作这 2 个领域。但是处于对生态破坏以及 AI 落地的的不确定性,小红书并没有大肆宣扬自己的 AI 产品。

近日,汤姆猫(SZ.300459)披露投资者关系活动,纪录表显示,汤姆猫正在研发的 AI 产品包括汤姆猫 AI 语音机器人、AI 讲故事 APP、 AI 游戏等系列产品。其中,第一代汤姆猫 AI 机器人产品预计春节前上市。

如今AI以一种不可阻挡之势,渗透在人们生活中的方方面面,成为引领未来发展的重要风口。AI聊天机器人作为人工智能领域的重要代表作之一,在全球范围内掀起了一场技术革命。

近期有一种影视剧解说方式流量暴增,用人物独白的方式解说电视剧,用家喻户晓几乎人人都看过的影视神剧里的某一个人物,以他的口吻用独白的方式来解说自己生平的故事,并且声音就是人物本身的音色。
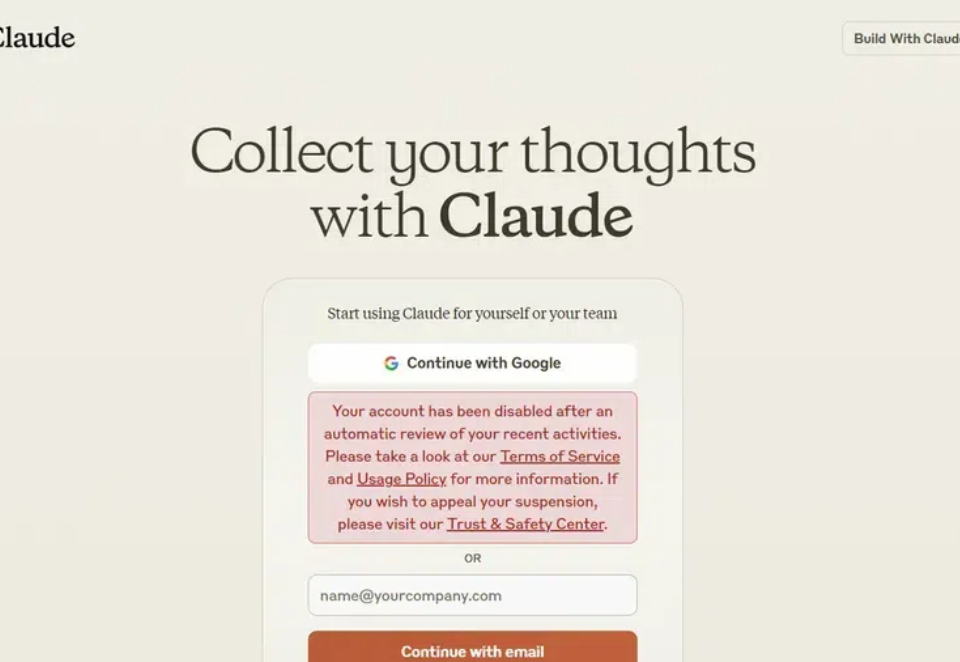
忙了一上午,我端着咖啡,习惯性地打开电脑,想和我的「数字大脑」Claude 开始干活。谁知道一个提示框直接把我打懵了—— Claude 账号被封了。那一刻, 手里咖啡不香了。

视觉模型仍是IDEA的研究重点——IDEA正式发布的最新通用视觉大模型DINO-X,可以拥有真正的物体级别理解能力。

小米公司成立于2010年,初期主要以 MIUI、小米手机、小米路由器和智能家居硬件研发为主。
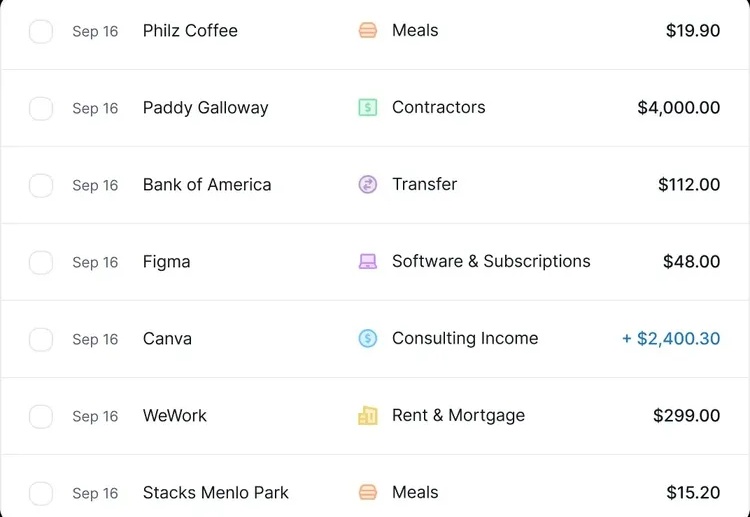
上月,一家名叫Kick的硅谷AI记账自动化公司宣布完成900万美元种子轮融资。尽管AI/FinTech领域一直是热门吸金板块,但Kick因其特殊的融资背景格外引人注目,因为它是OpenAI Startup Fund最早期的投资组合之一。
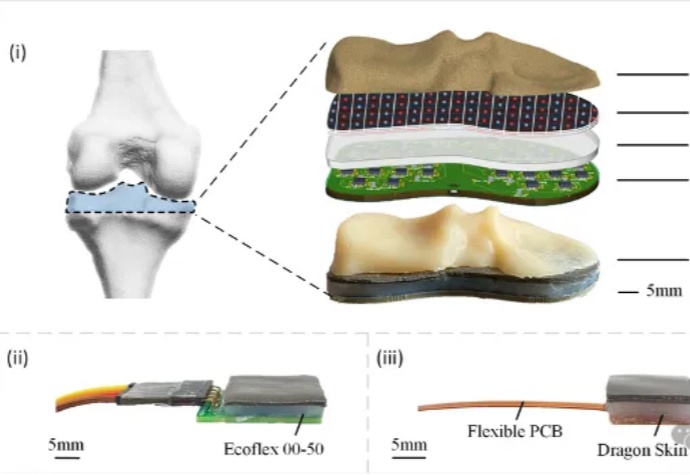
触觉是人类感知外部环境并与之交互的重要知觉形式。
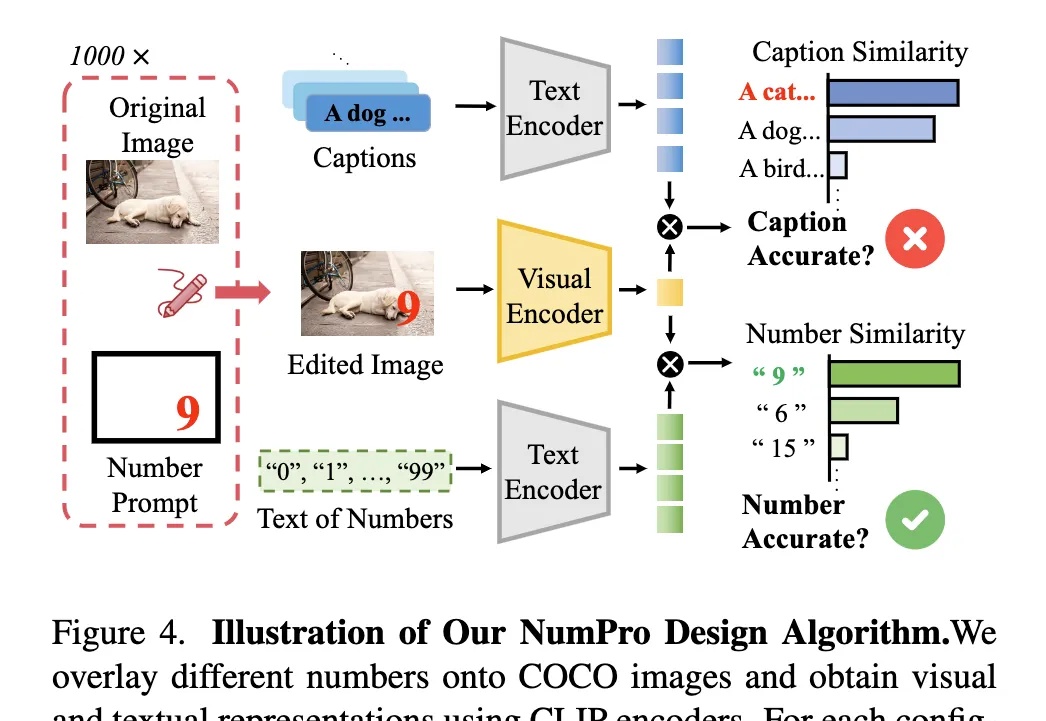
用看漫画的方式,大幅提升视频大模型时序定位能力!
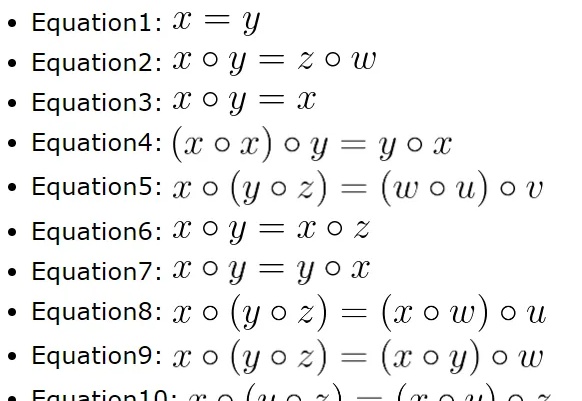
57天,人类和AI合作搞定了4694个等式之间22028942个蕴含关系!
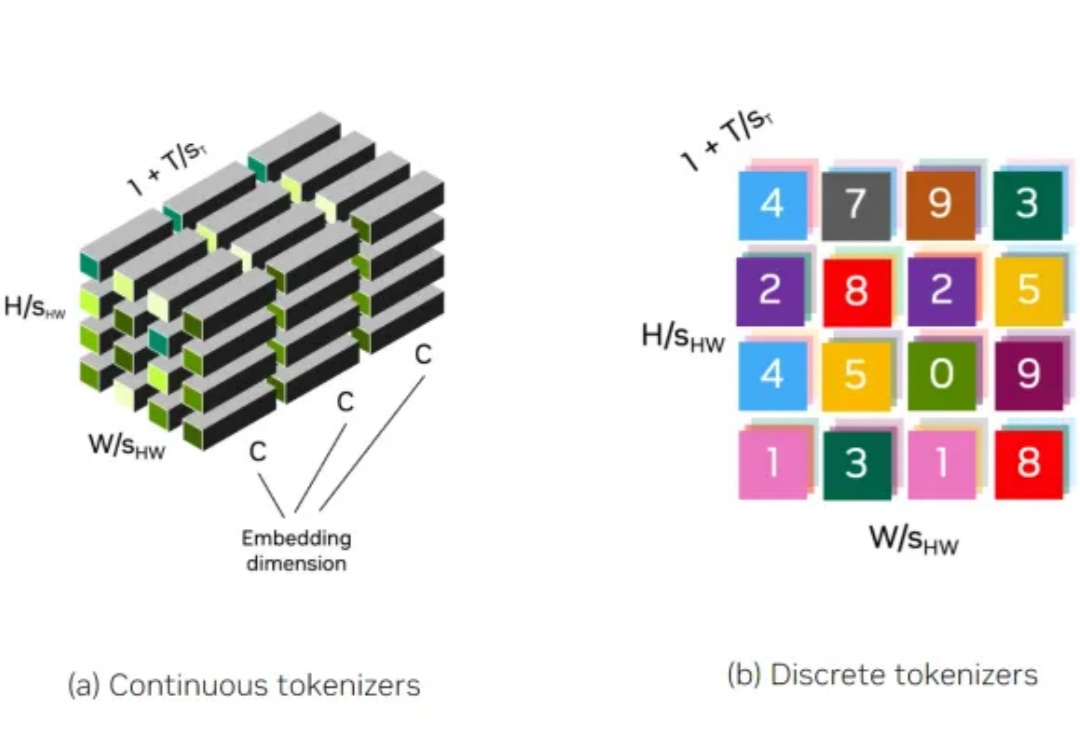
tokenizer对于图像、视频生成的重要性值得重视。
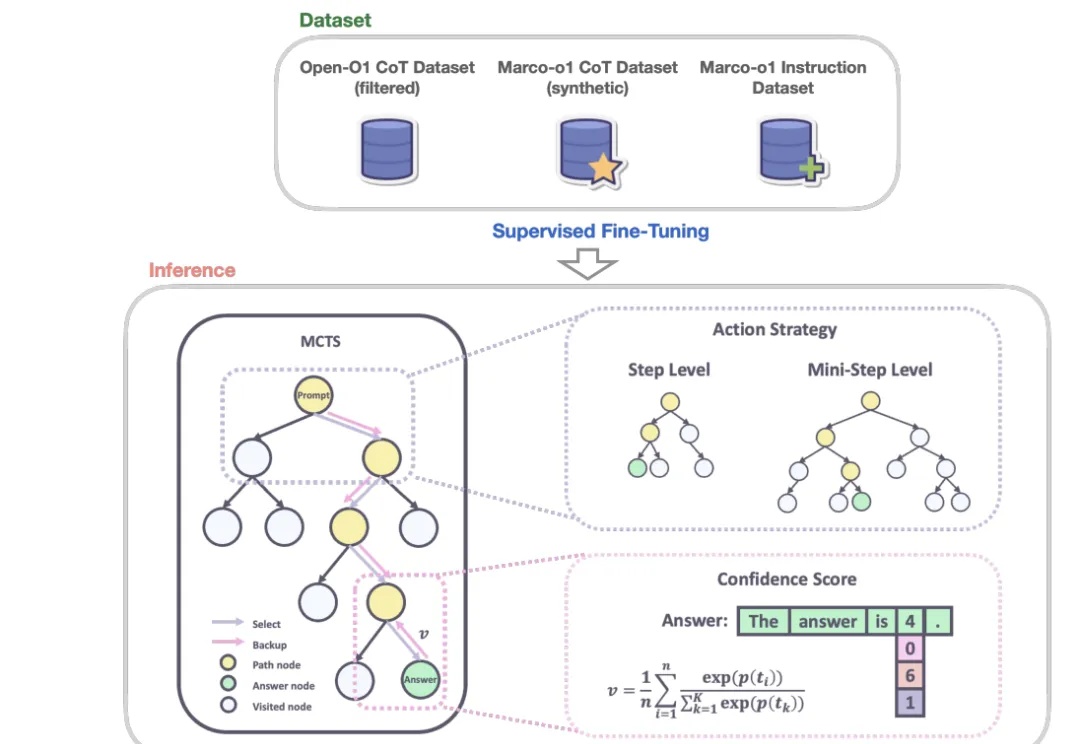
自从 OpenAI 发布 o1 模型以来,业界对其的追赶不断加速。

在各大科技公司纷纷竞相资助生成式 AI 之际,亚马逊正向 AI 初创公司 Anthropic 额外投资 40 亿美元。这将使亚马逊对 Anthropic 的总投资(自去年开始)达到 80 亿美元。
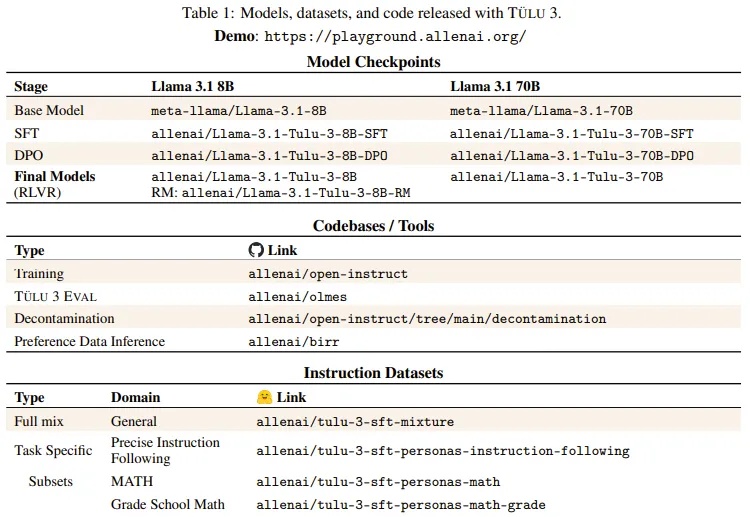
开源模型阵营又迎来一员猛将:Tülu 3。它来自艾伦人工智能研究所(Ai2),目前包含 8B 和 70B 两个版本(未来还会有 405B 版本),并且其性能超过了 Llama 3.1 Instruct 的相应版本!长达 73 的技术报告详细介绍了后训练的细节。

今年是谷歌学术创立20周年,创始人们特意为此撰写了一篇博客,回顾了谷歌学术的成长历程,并分享了一些实用的使用技巧和背后的趣闻轶事。在AI浪潮席卷而来之际,谷歌学术将如何站稳脚跟?
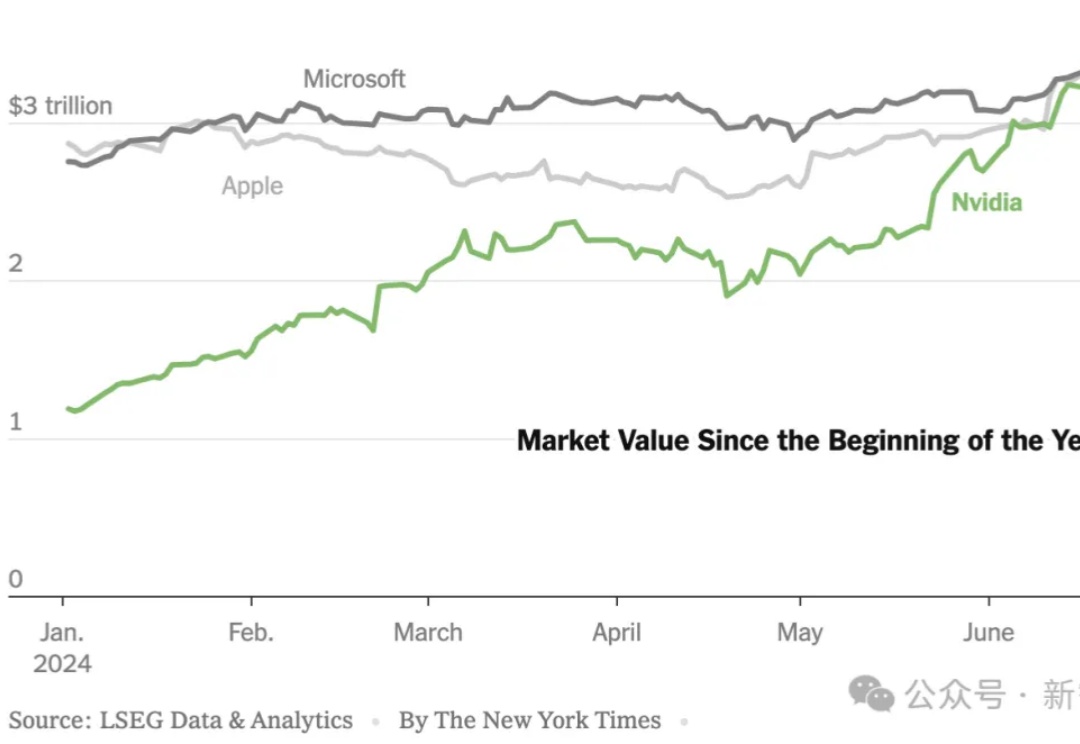
几十年来,英特尔一直是硅谷占主导地位的芯片厂家。但错失大好时机,加上糟糕的执行力,让这家公司在科技行业如火如荼的AI淘金热中被迫退居观望状态。

