

每月涌入 200 万首 AI 歌曲,Spotify 被逼得发「活人证」了
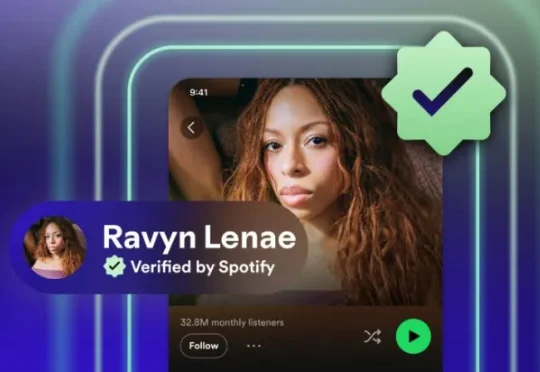
每月涌入 200 万首 AI 歌曲,Spotify 被逼得发「活人证」了2015 年,Spotify 推出了蓝色对勾。那时候验证的意思很简单:这个账号真的是 Taylor Swift 本人,不是粉丝自建页面。十年后,Spotify 又推出了一个新徽章,绿色的。这一次要说明的是,「这是个真人账号」。
来自主题:
AI资讯
9886 点击 2026-05-02 11:13
 搜索
搜索
2015 年,Spotify 推出了蓝色对勾。那时候验证的意思很简单:这个账号真的是 Taylor Swift 本人,不是粉丝自建页面。十年后,Spotify 又推出了一个新徽章,绿色的。这一次要说明的是,「这是个真人账号」。

EverMind 想做点不一样的。这家由盛大集团孵化的公司,定位是为所有AI Agent提供一个通用的"记忆层"(Memory Layer)。它的核心产品EverOS是一套开源的长期记忆系统,开发者可以把它接入自己的Agent,让AI不仅能记住用户的历史对话和偏好,还能像人一样对记忆进行整理、更新,甚至从过去的经验中学习和进化。
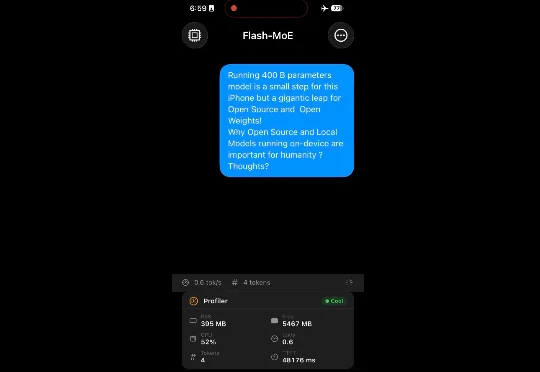
刚看到这个 Demo 的时候着实有些想笑,很久没有见过吐词如此之慢的大模型了。观感上就像「闪电」老师。尽管只有每秒 0.6 个 tokens 的输出速率,这依旧是一个令人不可思议的工作。因为这是一个跑在 iPhone 17 Pro 上的 400B 大模型!
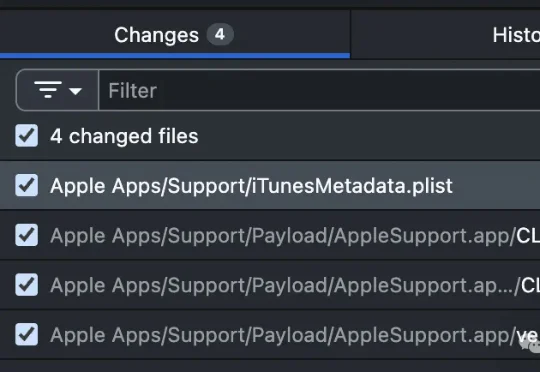
苹果大失误!把自用的Claude.md打包到了官方App里。 这下直接被坐实了:苹果内部在使用Claude Code构建生产级应用。这么大的公司,也在Vibe Coding?

从去年开始做这个账号以来,我其实写过不少测模型的文章。我相信也有很多朋友是因为看了我测评的文章关注我的。但从过年之后,真的就很少写模型评测的文章了。主要是我写文章的速度甚至一度跟不上模型发布的速度了。

你要是问当今互联网最神秘、最玄学、连量子力学都解释不清的「时空裂缝」在哪里?它不在百慕大,也不在诺兰导演的电影里,而是在你的 DeepSeek、Claude 或者 ChatGPT 正在思考的过程里。

OpenAI 昨天扔了一个重磅炸弹——ChatGPT 账户正式上线「高级账户安全(AAS)」模式,直接禁用密码登录、砍掉邮箱短信找回,逼你用物理安全密钥或 passkey。更狠的是,OpenAI 官方明说:
近日,AI编程智能体初创公司 Factory 完成1.5亿美元C轮融资,投后估值达到15亿美元,正式跻身独角兽行列。本轮由Khosla Ventures领投,Sequoia Capital、Blackstone、Insight Partners、Evantic Capital、20VC、NEA和Mantis VC参与跟投。


刚刚的消息,Cloudflare 联合 Stripe 发布了一份新协议,Agent 现在可以独立成为 Cloudflare 的客户。它能自己创建账户、订阅付费方案、注册域名、拿到 API token,然后直接部署代码

OpenAI刚刚投下了一枚重磅炸弹:原本作为程序员「副驾驶」的Codex迎来史诗级更新,正式从代码工具进化为通用个人助理,奥特曼亲自下场带货。开发者实测后惊呼:Codex接管整台Mac,人类全程0操作围观,太炸裂了!
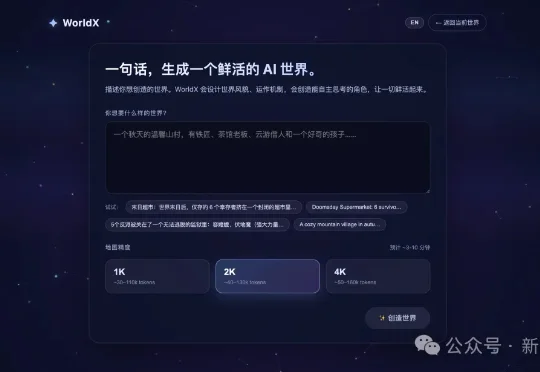
2023年斯坦福「AI小镇」火了,后续也诞生了大量类似的热门项目,但所有这类项目都有一个共同瓶颈——世界是人工搭建的,固定的。最近,一位独立开发者用10天婚假爆肝了一个项目WorldX:输入一句话、5分钟,一个完整的AI世界就诞生了——地图、角色、动画、人设全部自动生成,AI角色们自主在其中生活、对话、形成记忆、产生戏剧性的涌现行为。
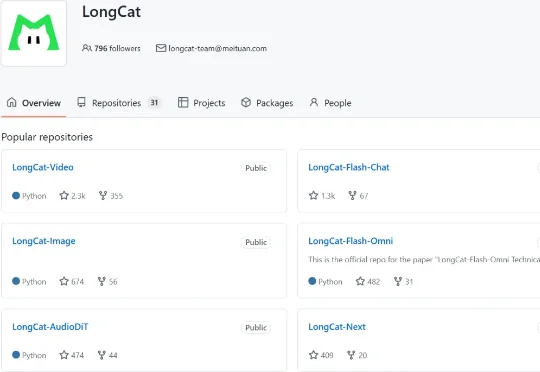
一边是 DeepSeek。2026 年 4 月 24 日,正式发布新一代模型DeepSeek-V4 系列预览版,并同步开源。另一边,美团闷声干了件大事——用全国产算力集群,训练出了万亿参数大模型 LongCat-2.0 系列预览版( LongCat-2.0-Preview )。
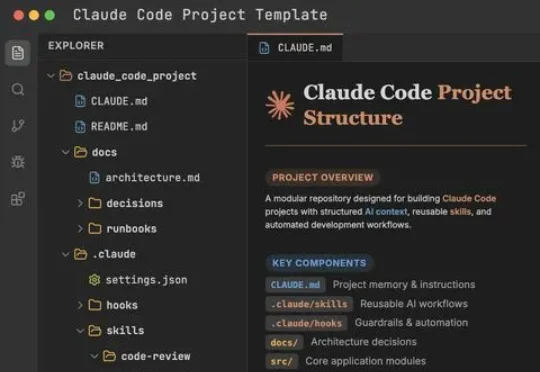
你还在ChatGPT的聊天框里反复调prompt?最近,一位X用户发了条推文,开头就是一个惊呼:头部大厂偷偷在用的Claude Code项目模板外泄!这已经不是写提示词了。这是AI工程基础设施。

AI界深水炸弹!4月29日,Anthropic被爆正在谈判新一轮融资,估值可能突破9000亿美元。如果交割完成,这家成立不到四年的公司将一举超越OpenAI,成为地球上最贵的AI独角兽。

可能还有些人记得,去年年底的时候,Anthropic 在自家办公室搞了一个自动售货项目,「主理人」是 Claude——哦不,主理机。当时是让 Claude Sonnet 3.7 在办公室里经营一台自动售货机,管进货、定价、跟同事聊天推销,干了大概一个月。结果
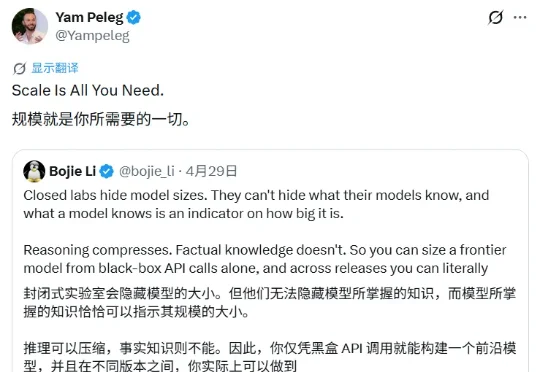
基于此,研究者在 89 个参数量已知的开源模型(规模从 1.35 亿到 1.6 万亿参数)上拟合出事实准确率与参数量的对数线性关系,拟合优度 R² = 0.917,并据此对闭源模型进行参数估算。

GEO服务商每天往互联网里灌多少内容? 一家中型GEO公司,在部分批量化运营模式下,月度内容产出可以达到很高规模。背后是自动发稿机、批量账号、几乎一模一样只换了平台名字的通稿。逻辑很简单,他们认为铺得

在 AGI-Next 前沿峰会上,腾讯姚顺雨举了一个很生活化的例子:当你问 AI “今天吃什么” 时,真正限制答案质量的,可能不是模型不够大,也不是推理不够强,而是它不知道你今天冷不冷、想不想吃热的、最近和朋友聊过什么、家人又有什么偏好需要纳入考虑。


ElatoAI 是一个开源免费的实时AI语音交互系统,采用Arduino 编程,运行在乐鑫 ESP32 主控制器上,通过安全WebSocket连接至部署在Deno边缘函数构建的服务端,通过OpenAI Realtime API等技术实现低成本、长时长、跨设备的自然对话体验,支持多种AI模型,

3 月 30 日,爱奇艺正式官宣发布的专业级影视制作平台纳逗 Pro,正是其中代表。通过将行业领先基座模型与爱奇艺深耕多年的影视内容制作经验深度结合,纳逗 Pro 直接将目标对准了电视剧、院线级内容从剧本生成、分镜设计到成片输出的创作全流程。

魔法原子在会上推出了新一代人形机器人 MagicBot X1 和灵巧手 MagicHand H01,而且第一次把其世界模型 Magic-Mix、数据生成与训练反馈闭环,作为一套完整的具身智能底层能力集中展示出来。

AI科技评论从多处独家获悉,前蔚来 AI平台负责人白宇利已创立新公司“上海补天石科技”,公司业务聚焦具身数据Infra方向。企查查信息显示,上海补天石科技有限公司于2025年11月成立,法人正是白宇利。
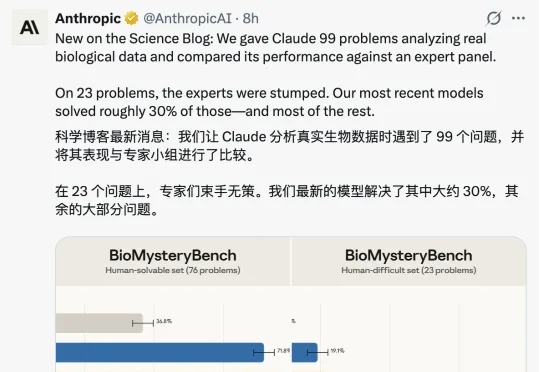
今天 Anthropic 放出了一项评估数据,对于新的生物信息学评测集 BioMysteryBench:人类能搞定的,Claude 也能搞定;在人类搞不定的,Mythos 也能搞定
8人团队干10个月,AI只需一夜!英伟达祭出「造芯」神技:芯片设计效率狂飙百倍,非人类直觉的设计方案惊呆工程师。硅基生命开始自进化,人类正退居二线?进来看黄仁勋的秘密武器。

GPT Image 2的发布给整个AI圈带来了亿点点震撼。但很多人可能没注意到,幕后最会玩梗的居然是他——主力训练者陈博远。他和奥特曼同台主持,悄悄修好了中文渲染;给模型起代号“布基胶带”,还拿香蕉艺术品玩梗;为了秀模型的文字能力,设计了米粒刻字、漫画套娃、视觉证明题这些“彩蛋级”测试。

这不是恐怖故事,也不是田螺姑娘的寓言故事,而是 3 月 17 日,HooRii 在 Kickstarter 上线的众筹项目「ClawStage」的宣传。它的定位是“OpenClaw 的现实世界游乐场”——用一个小方块,让 OpenClaw 来到现实世界,并能担任你的家庭管家。
《DT商业观察》留意到,即便是电商常见的“图搜找同款”场景,自从淘宝图像搜索产品@拍立淘新上线了“AI模式”,把“图搜”功能进化成“启发式图搜”,用户的玩法也已升级。

谷歌母公司Alphabet营收达到1099亿美元,每股收益5.11美元,远超华尔街预期的2.62美元;亚马逊净销售额1815亿美元,净利润303亿美元,每股收益2.78美元,几乎是预期的两倍;微软营收829亿美元,同比增长18%;Meta净利润268亿美元,同比接近翻倍。

