


突发,马斯克xAI解散了!22万张GPU忍痛全给Claude
突发,马斯克xAI解散了!22万张GPU忍痛全给Claude今天,马斯克官宣解散xAI并入SpaceX。同时,他把全球最强超算Colossus 1,全部租给OpenAI死对头Claude。一边在法庭要罢免奥特曼,一边给对手送算力,老马这波釜底抽薪绝了。
来自主题:
AI资讯
8102 点击 2026-05-07 11:02
 搜索
搜索
今天,马斯克官宣解散xAI并入SpaceX。同时,他把全球最强超算Colossus 1,全部租给OpenAI死对头Claude。一边在法庭要罢免奥特曼,一边给对手送算力,老马这波釜底抽薪绝了。

OpenAI 揭晓了 ChatGPT Futures 项目,为 37 名年轻人提供了 1 万美元的无偿资助、前沿模型访问权限,并邀请他们 6 月去总部参访
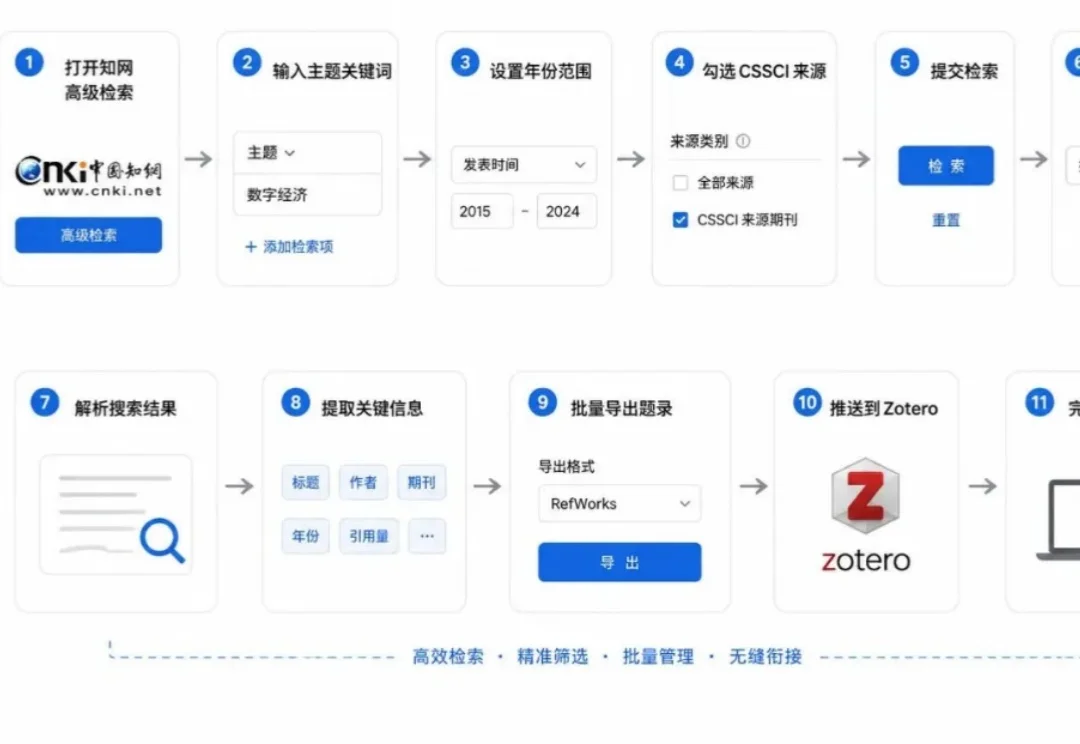
做文献调研时,很多人的流程大概是这样的:
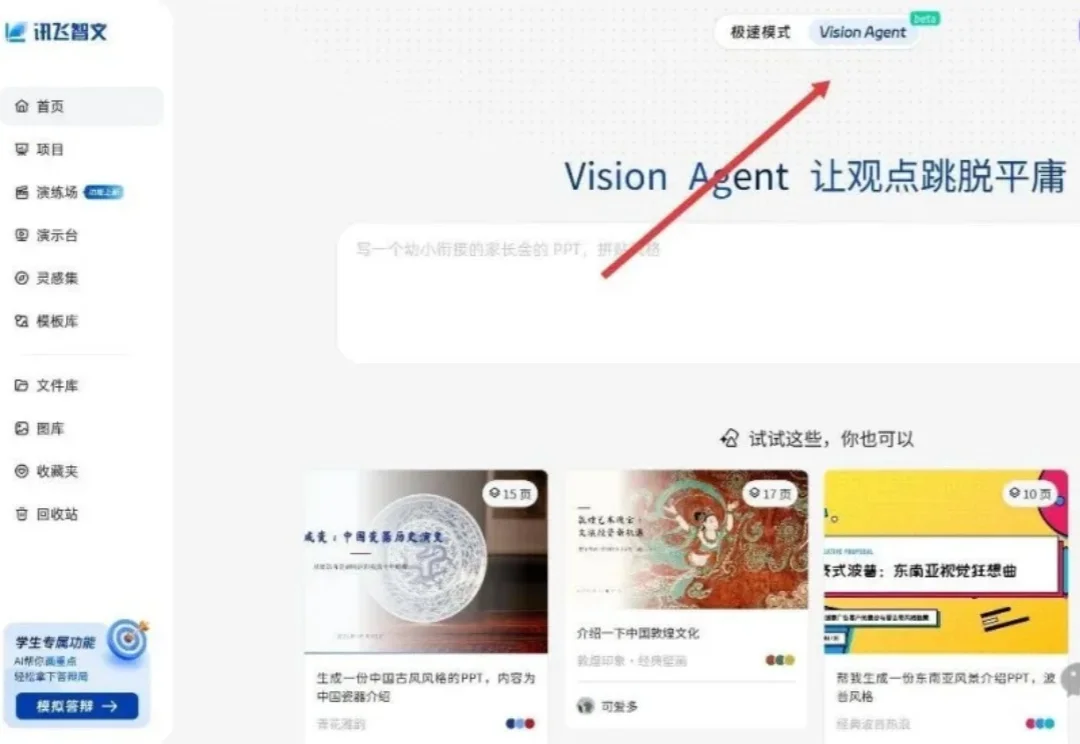
过去一两年,AI做PPT这事儿一直处在一个比较尴尬的位置。

我最近买了一个这样的键盘——

Transformer统治地位悬了!一款SubQ模型带着SAA架构横空出世,1200万上下文成本仅Opus的5%,计算量暴减千倍。
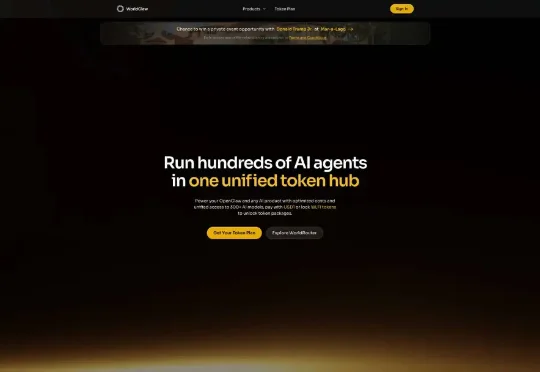
太魔幻了,特朗普开始做API中转站了,还有七折的 Claude 可以用。甚至还有机会参加懂王的私人派对。前两天还在跟朋友感慨,连孙雨晨都低调下场搞中转站了,AI API 这门生意是真的下沉到水深火热了。

今日,云启种子轮领投项目「魔形智能」宣布完成数亿元人民币 Pre-A 轮融资。自成立以来,魔形智能围绕“Token 超级工厂”持续构建技术与交付能力,专注于为全球 AGI 产业提供高性能、高质量、高附加值的 Token 产品。

《读佳》获知,蚂蚁集团正在开发一款名为“Muse”的产品,该产品或为灵感创作类的AI产品,主打让灵感轻松成真,产品的中文名可能叫做“巧妙思”,由于产品还在开发,具体产品形态及相关信息请以官方为准。
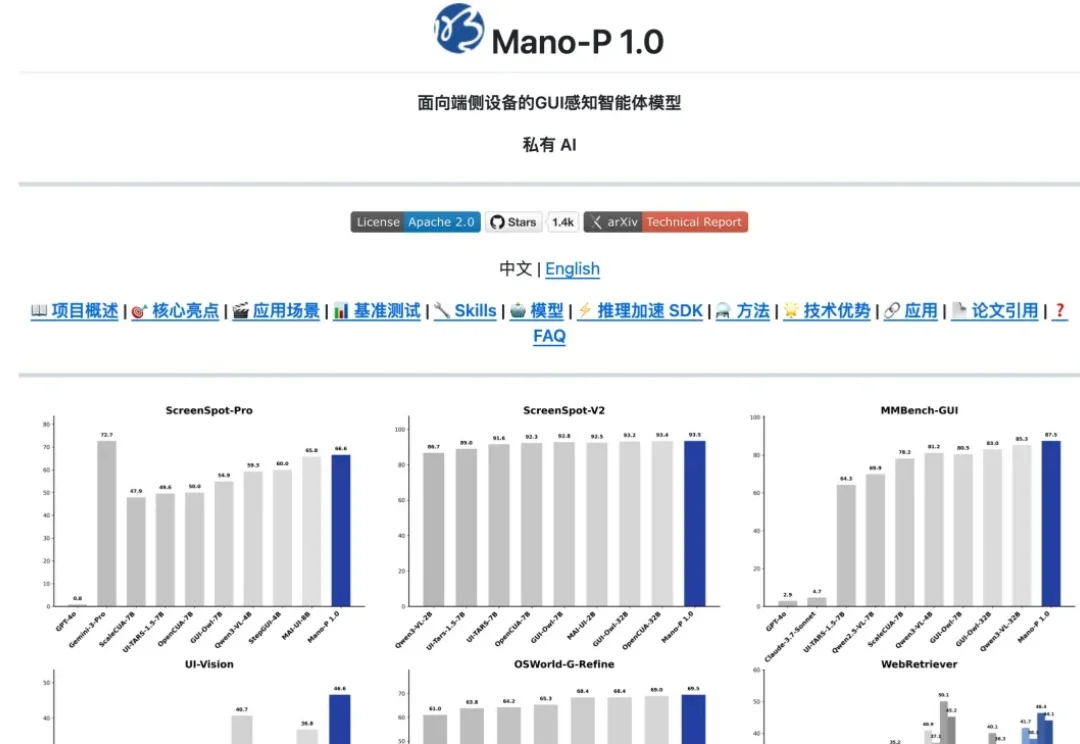
上次给大家分享了一个 CUA 的开源项目,能让 AI Agent 直接操控电脑界面,相当于把任何 App 都变成 Agent 的 Skill。反响还不错。
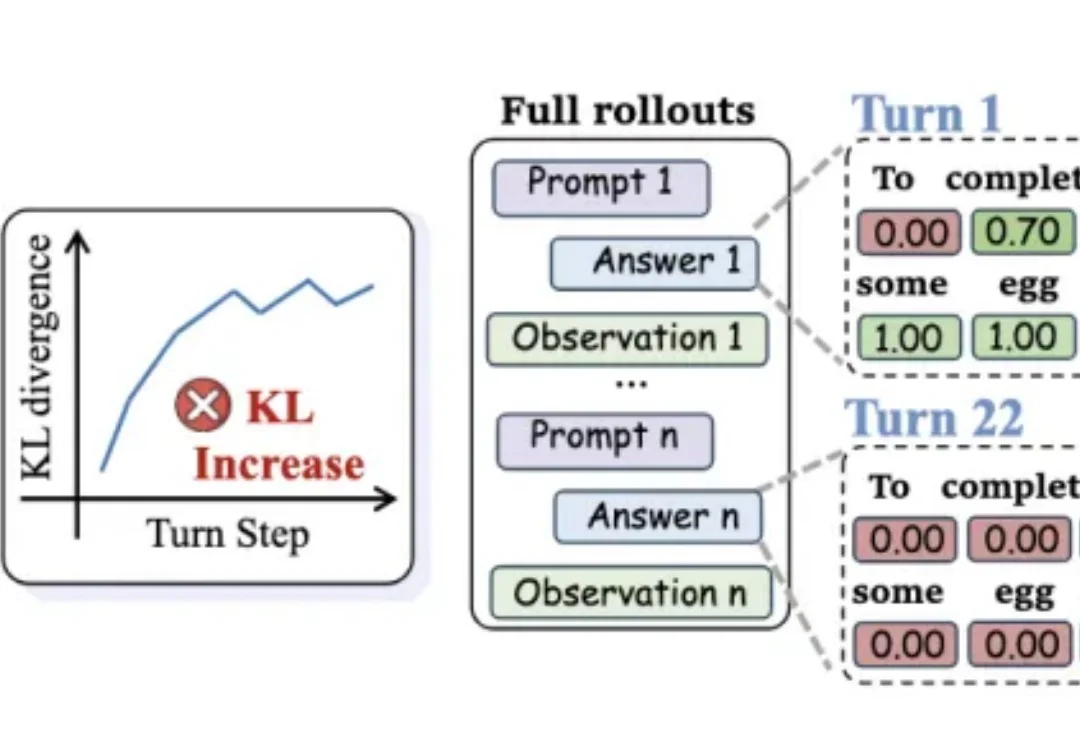
把强大模型的能力“蒸馏”给小模型,听起来很美—— 但放到多轮对话Agent场景里,效果往往一塌糊涂。

Agent Skills不应该只以SKILL.md、README或自然语言说明文档的形式存在,而应该被转成一种机器可检索、可检查、可治理的结构化表示。这是《From Skill Text to Skill Structure: The Scheduling-Structural-Logical Representation for Agent Skills》这篇论文的核心主张。

当Agent开始真正进入生产环境,安全问题不再是「功能模块」,而是贯穿调用链、运行时与生态层的系统性风险。过去依赖提示词规则、日志审计与框架级防护的方式,正在逐步失效。来自清华大学人工智能学院、交叉信息研究院的方寸跃迁提出一套面向Agent运行全生命周期的多层安全体系。

大模型时代的「炼金术师」们,或许都曾面临一个共同的困扰:当我们试图将 DeepSeek-R1、OpenAI-o1 那种惊艳的推理能力迁移到小规模语言模型(SLMs)时,效果却总是差强人意。现有的强化学习方法如 GRPO 在 7B+ 的大模型上效果显著,但一旦应用到 1.7B 甚至更小参数的模型上,性能提升就微乎其微。

陶哲轩+AI再上大分!

Salesforce CEO Marc Benioff近日甩出一份招聘计划:要一口气招进1000名应届生或实习生,与他们一起搭乘AI快车。IBM更猛,北美入门级岗位直接扩招3倍,麦肯锡、Cognizant紧跟其后。智能体时代,一批10年前根本不存在的「金饭碗」正在批量诞生,应届生这个词,也将被重写。

Anthropic宣布与SpaceX达成合作协议,将大幅提升算力储备。受此影响,Claude Code和Claude API的使用限制即日起全面上调。第一,Claude Code的5小时频率限制翻倍,适用于Pro、Max、Team以及按席位计费的Enterprise方案。

在对多位内部开发者的采访中得知,这个模型的研发已被叫停。LPM 1.0 并非仍在推进的核心项目,而是视频团队对过去一年工作成果的集中汇报——既是对外展示,也是对内总结。该视频团队由“童姥”( 前微软亚研院首席研究员童欣) 带领, AilingZeng做Tech Lead,作者中近半数来自 Anuttacon内部,蔡浩宇本人并未直接参与模型研发。

Assort Health 是一家值得被认真拆解的初创公司。成立仅两年多,累计融资1.015亿美元,拿着300万美元的ARR(年度经常性收入),却获得了7.5亿美元的估值。Assort 最近推出主动式互动引擎 Activate,从被动接听到主动做患者唤醒和慢病管理,这已经是在为真正面向用户的智能体做铺垫了。
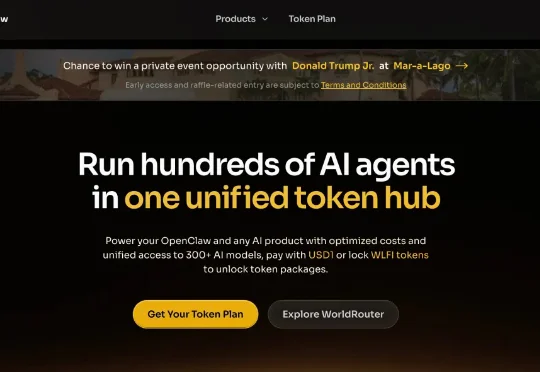
懂王开始做 API 中转站了,还七折的 Claude 的 API。买多了,还抽送懂王的私人晚宴名额!项目叫 WorldClaw,可以理解为 OpenRouter 的懂王版,在这里,需要用懂王的加密货币 WLFI 结算,聚合了 300 多个 AI 模型,声称比官方定价低 30%

AI 员工得能和真实的人交流,能接收文件,能在一个稳定的环境里持续运转。GenSpark 4.0 在这一层做得很到位。它可以和联系人直接对话,并且原生集成了 MyClaw,不需要用户自己去安装 OpenClaw 再配置到飞书或微信。

英国AI音频独角兽ElevenLabs披露了其D轮融资新的投资者,同时透露其ARR(年度经常性收入)已突破5亿美元(约合人民币34.1亿元)。奥斯卡影帝杰米·福克斯、演员伊娃·朗格利亚等30余位创意人士首次成为股东。

据金融时报的最新消息,多家机构目前正寻求领投 DeepSeek 的首轮融资。如果谈判顺利,DeepSeek 在本轮的估值将达到约 450 亿美元。短短几周内,DeepSeek 的估值就从刚开始被爆料的 200 亿美元一路狂飙翻倍。

独家获悉,Kimi (月之暗面)即将完成新一轮 20 亿美元融资,投后估值突破 200 亿美元。本轮融资由美团龙珠领投,中国移动、CPE(中信产业基金)等参投,其中仅龙珠就出手超 2 亿美元。

2026 年 3 月底,Ollama 发布了一则更新公告:其 Mac 版本的底层推理引擎,将从沿用多年的 llama.cpp 切换为苹果的 MLX 框架。

OpenAI版“豆包手机”,正在开足马力前进。

2026年5月4日,testingcatalog在Anthropic的Web/Mobile客户端里挖出隐藏功能Orbit。5月6日,Code with Claude大会在旧金山开幕。Orbit不等你开口就从Gmail、Slack、GitHub里替你干活了。
李飞飞又拿到钱了。5600万美元。
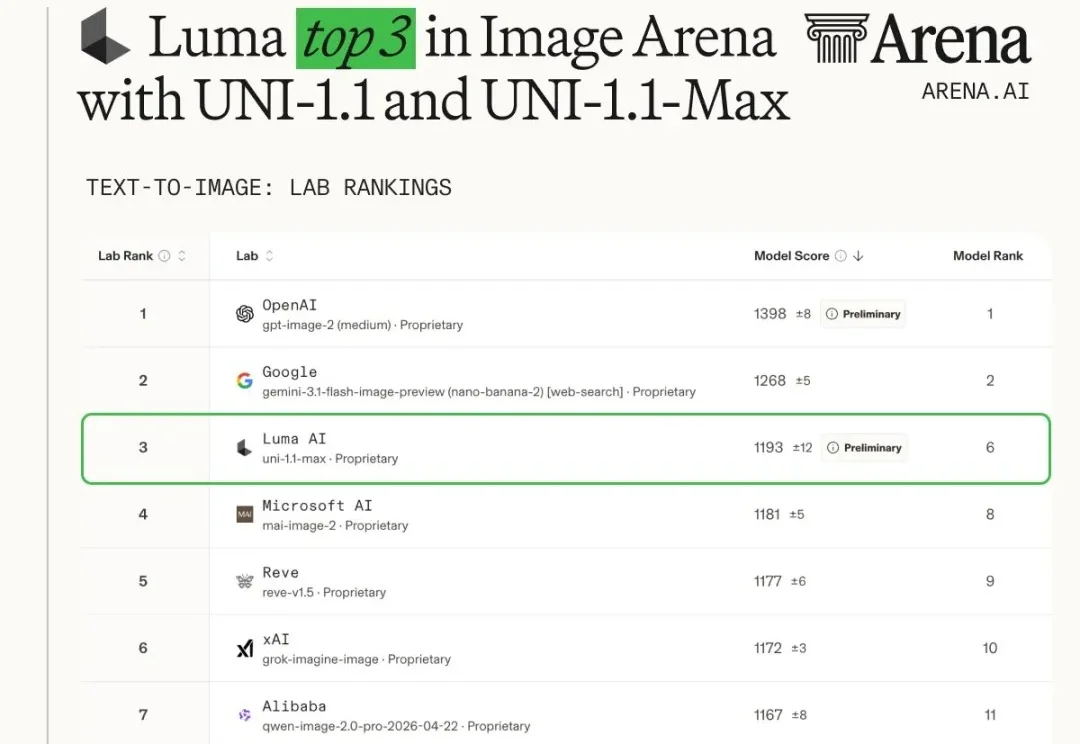
今年以来,图像生成模型的迭代节奏明显加快。

OpenAI 成立前夜,核心大脑 Ilya 差点反悔,选择继续留在谷歌。

