


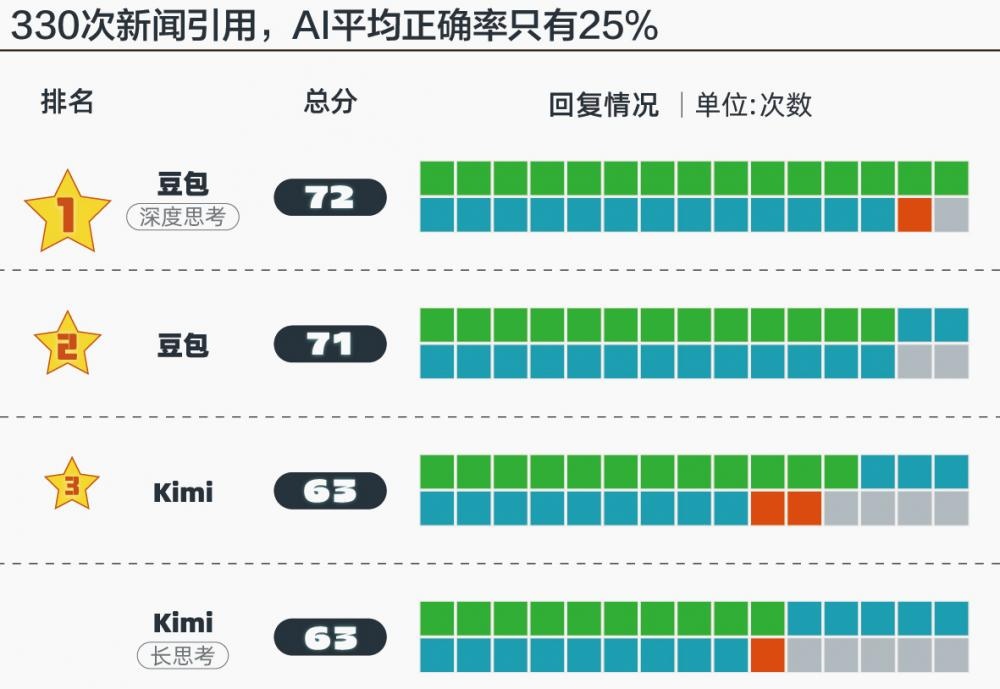
“HR抢着加微信”,这个行业,实习生月入过万
“HR抢着加微信”,这个行业,实习生月入过万AI实习岗日薪达千元,技术岗高薪学历门槛高。
来自主题:
AI资讯
8479 点击 2025-04-11 15:51
 搜索
搜索
AI实习岗日薪达千元,技术岗高薪学历门槛高。

设计软件提供商 Canva 公司推出创意 AI 产品,加强其生成式人工智能服务,试图在迈向首次公开募股之际,从竞争对手 Adobe 公司那里吸引企业客户。

好莱坞科幻大片《铁甲钢拳》就这样被宇树机器人实现了?!

AI 与 SaaS 的结合,有哪些可能性?

印度人工智能初创公司 Ziroh Labs ,与该国顶尖技术学院的研究人员合作,设计出一套经济实惠的系统,据称无需依赖英伟达公司等提供的高端计算芯片,即可运行大型 AI 模型。
美国宣布对所有贸易伙伴加征“对等关税”的消息持续动荡,这几天里,手机里的新闻弹窗爆炸,不同地区、不同行业的关键词在标题里轮番滚动。

蚂蚁集团副总裁、前百灵大模型一号位徐鹏(花名:无改),已于近日离职;此外,据「市象」了解,基于蚂蚁百灵大模型的AI应用支小宝团队也在近期面临团队人员调整。

大家还记得那个 ICLR 2025 首次满分接收、彻底颠覆静态图像光照编辑的工作 IC-Light 吗?

报告深入分析了特朗普总统于2025年4月2日宣布的“解放日”关税措施对美国人工智能(AI)基础设施建设、相关供应链以及全球贸易格局的潜在影响。

近日,AI感知与边缘计算芯片研发商:爱芯元智完成超10亿C轮战略融资。本轮投资方为宁波通商基金、镇海产投、重庆产业投资母基金、重庆两江基金、元禾璞华、韦豪创芯等知名投资机构。
随着技术的深入应用,如何高效利用大模型技术优化用户体验,同时应对其带来的诸多挑战?本文将从RAG的发展趋势、技术挑战、核心举措以及未来展望四个维度总结我们应对挑战的新的思路和方法。

关税对算力产业链的影响正在产业链传导,H200终端涨价已成定局。之前英伟达设备是美禁止出口,并不是中国禁止进口,很多美国法律法规,中国根本不需要去遵守,所以H200 这些设备是正常报关,清关的。

杨杰表示,具体来看,AI的“规模效应”持续深化,呼唤基础设施新架构。作为数智化革命的重要驱动力量,AI发展呈现“两个规模效应”。在“两个规模效应”驱动下,AI任务成为算网基础设施承载的主要内容,到2030年在全网流量中的占比将达到64%。这一变化将对算网基础设施架构创新提出迫切需求。

ChatGPT可以引用过去所有聊天了!

FramMe的出现,让沉寂已久的修图赛道迎来新的“搅局者”。

在 Gemini 的爆火之后,Google Cloud 正在成为真正意义上的「基础设施」。

近日,星尘智能连续完成A轮及A+轮融资数亿元,由锦秋基金、蚂蚁集团领投,云启资本、道彤资本等老股东跟投,华兴资本担任独家财务顾问。
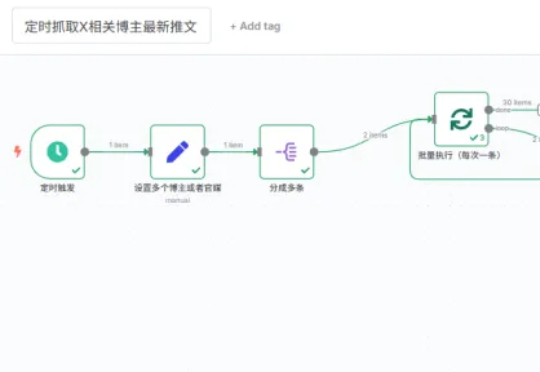
前两天给大家分享了一个我认为最强的开源AI Workflow平台:n8n。经过这几天的研究,我用n8n实现了一套超实用的X(原Twitter)热点监控workflow(工作流)。它由两个workflow(工作流)组成
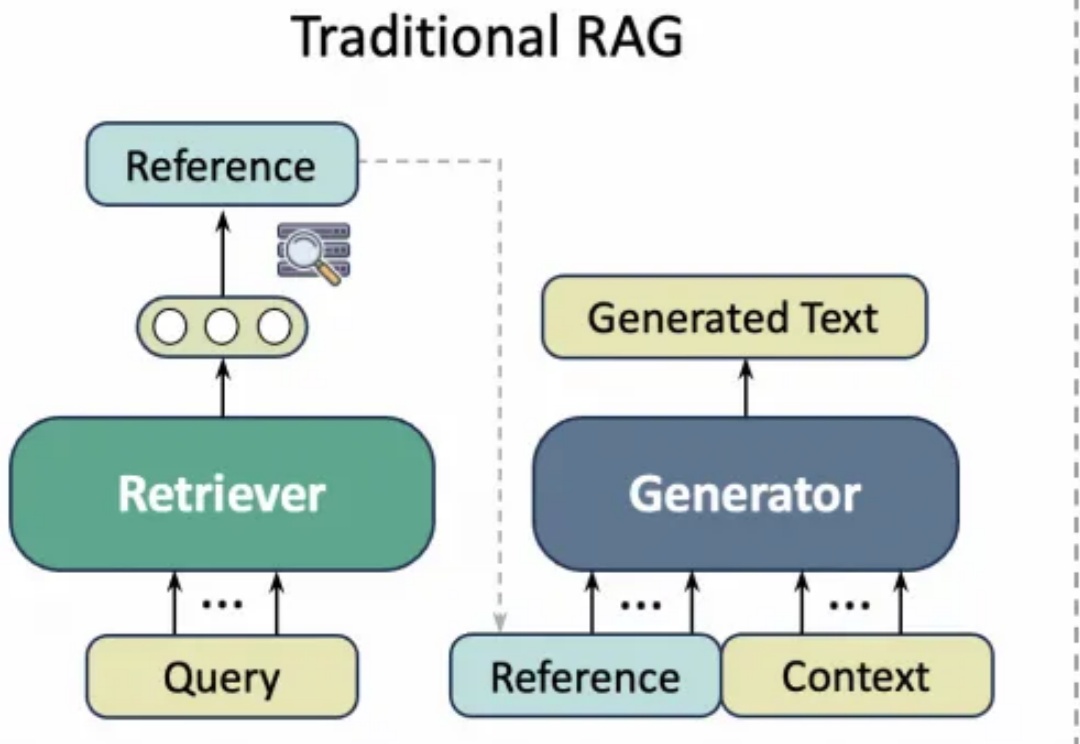
学术写作通常需要花费大量精力查询文献引用,而以ChatGPT、GPT-4等为代表的通用大语言模型(LLM)虽然能够生成流畅文本,但经常出现“引用幻觉”(Citation Hallucination),即模型凭空捏造文献引用。这种现象严重影响了学术论文的可信度与专业性。
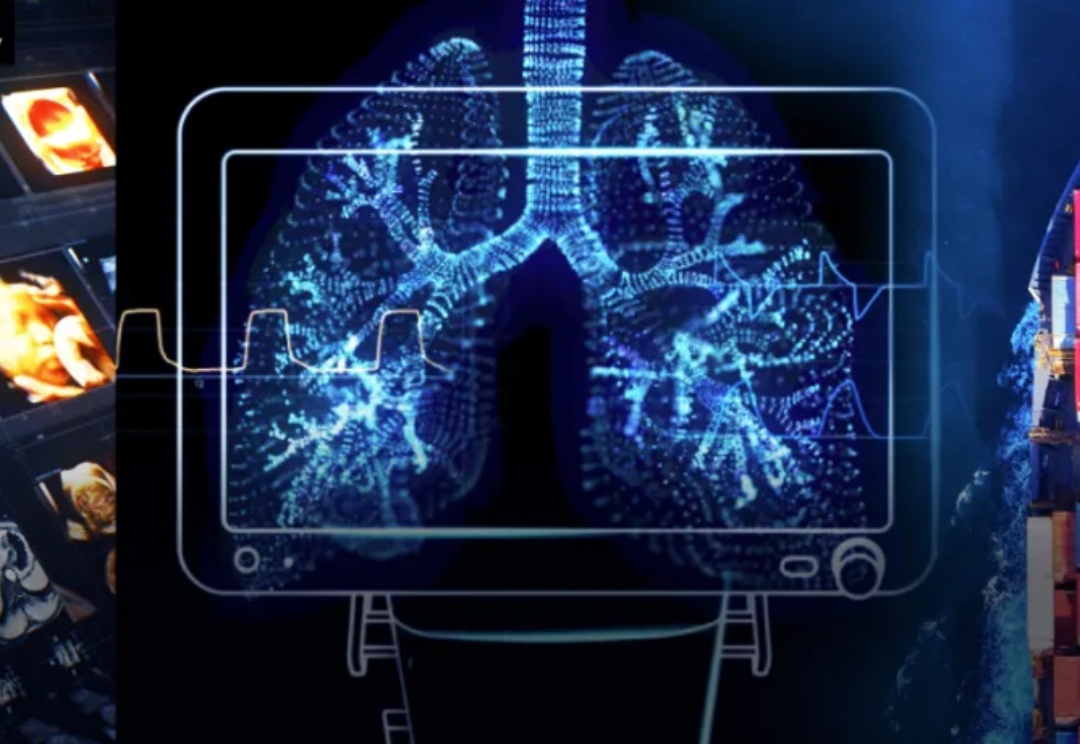
当下,中国医疗行业正迎来一场硬核突围的历史性转折。面对供应链断裂、技术垄断多重封锁,国产医疗三剑客以技术为剑,以创新为盾,强势打破技术护城河。这将是一场从「跟跑」到「领跑」的逆袭之战。
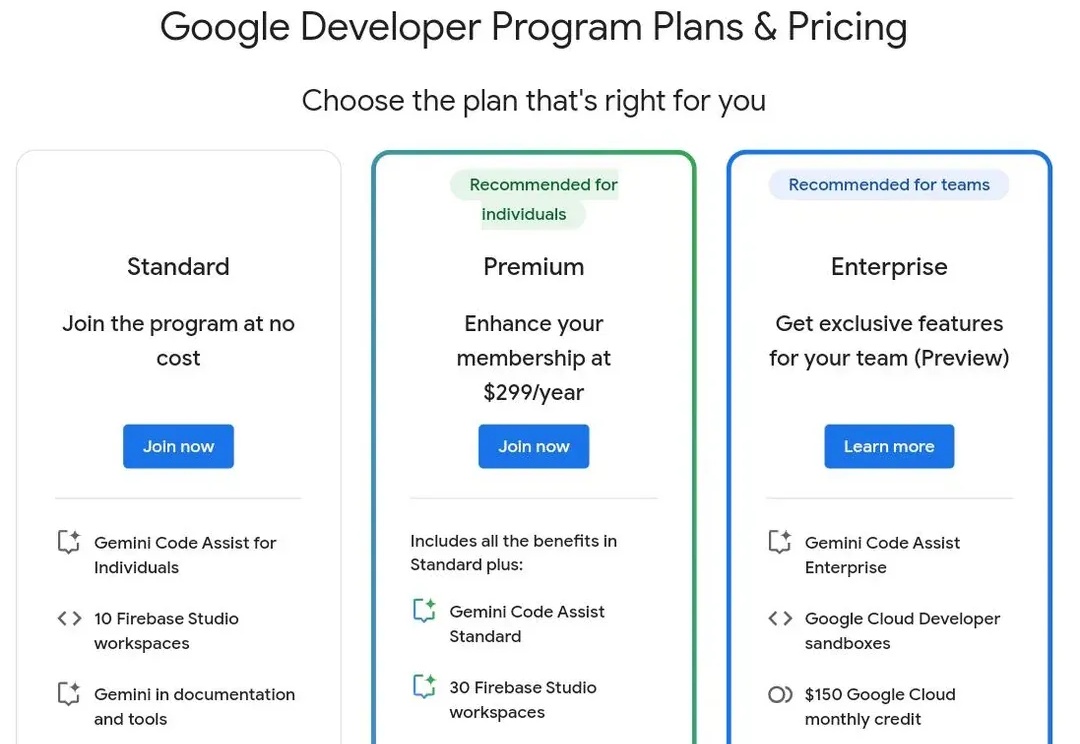
刚刚,xAI 正式上线 Grok 3 API,一次性推出4种模型,以适配不同应用场景,定价策略灵活,用户可按需选择。同日,谷歌、Anthropic等也推出新的定价策略。
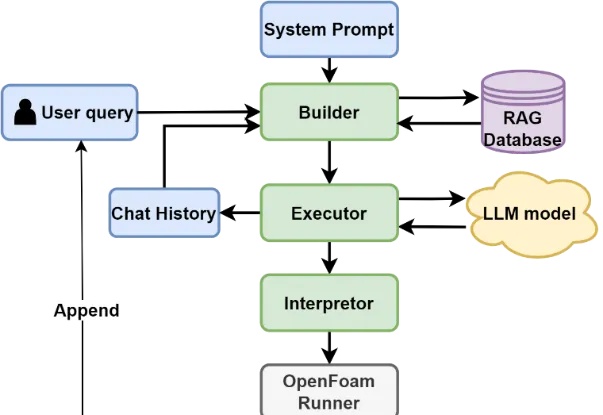
又一专业领域成功引入AI工程师!

在现实世界中,如何让智能体理解并挖掘 3D 场景中可交互的部位(Affordance)对于机器人操作与人机交互至关重要。所谓 3D Affordance Learning,就是希望模型能够根据视觉和语言线索,自动推理出物体可供哪些操作、以及可交互区域的空间位置,从而为机器人或人工智能系统提供对物体潜在操作方式的理解。
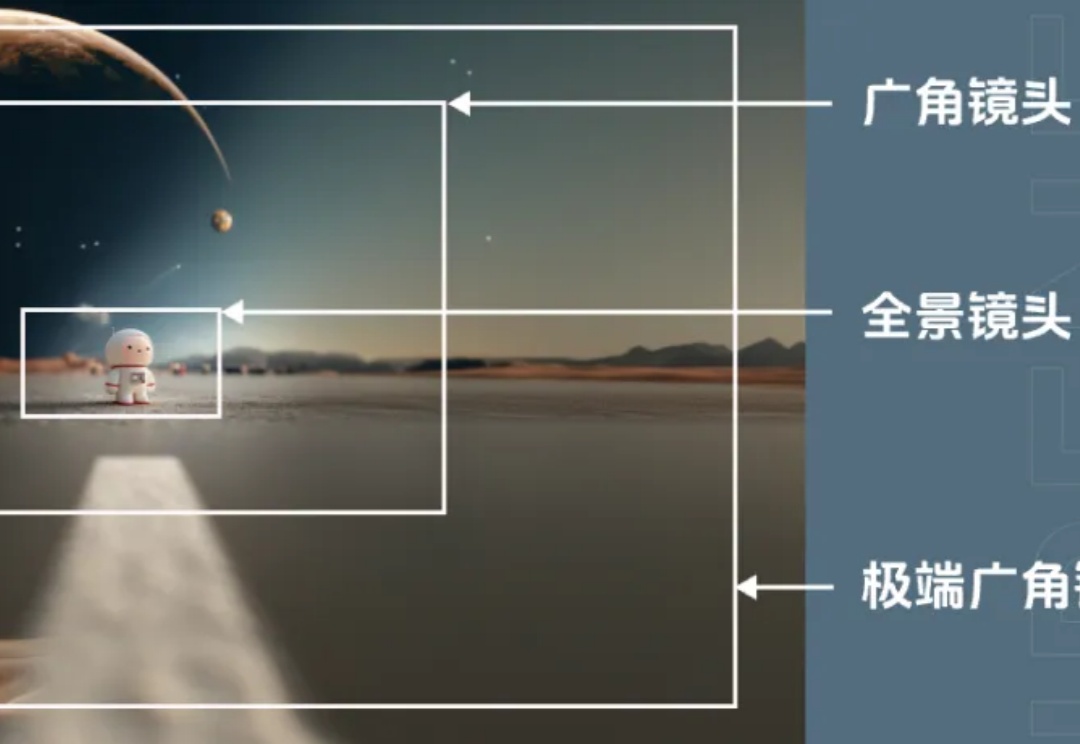
一直以来大多数时候都是直接告诉大家一张图的提示词是什么,且现在有更多工具和AI加持,写提示词也变得越来越简单几乎没有门槛,但是关于如何通过提示词更加精准控制画面得到自己想要的效果,其实还是有很多地方可以细说的。

港中文、清华等高校提出SICOG框架,通过预训练、推理优化和后训练协同,引入自生成数据闭环和结构化感知推理机制,实现模型自我进化,为大模型发展提供新思路。
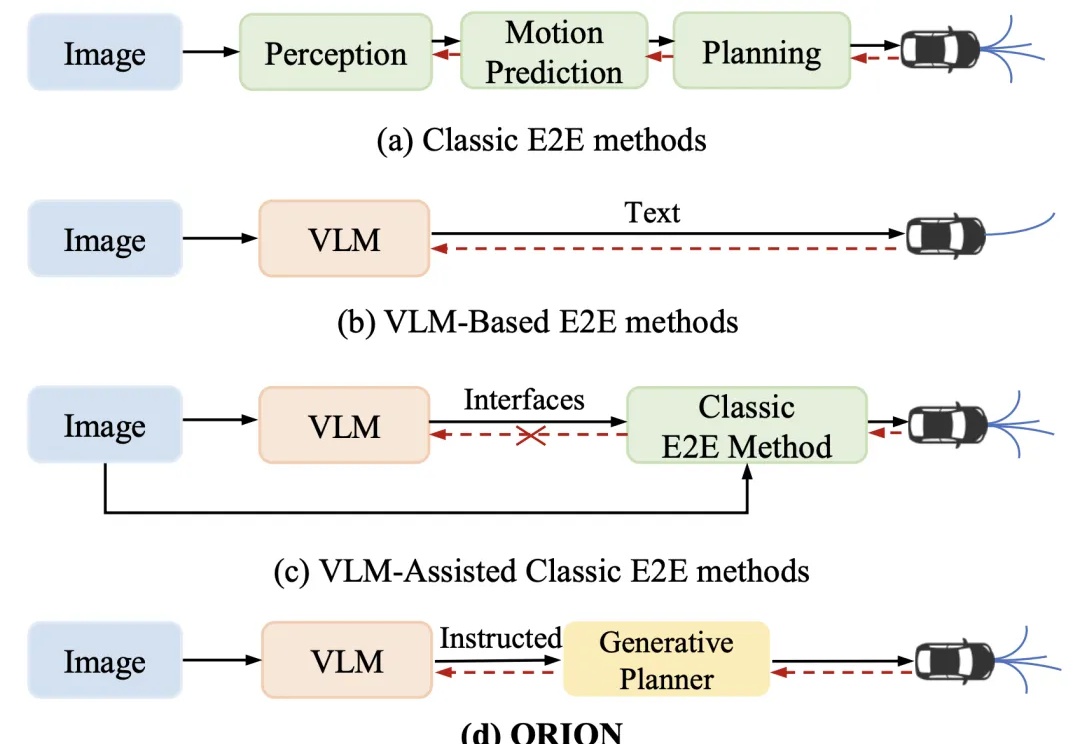
近年来,端到端(End-to-End,E2E)自动驾驶技术不断进步,但在复杂的闭环交互环境中,由于其因果推理能力有限,仍然难以做出准确决策。虽然视觉 - 语言大模型(Vision-Language Model,VLM)凭借其卓越的理解和推理能力,为端到端自动驾驶带来了新的希望,但现有方法在 VLM 的语义推理空间和纯数值轨迹的行动空间之间仍然存在巨大鸿沟。

今天早上看到 Google 开完了他们的 Google Cloud Next 25,发了近 20 个 AI 相关的模型、应用、开发工具、硬件。
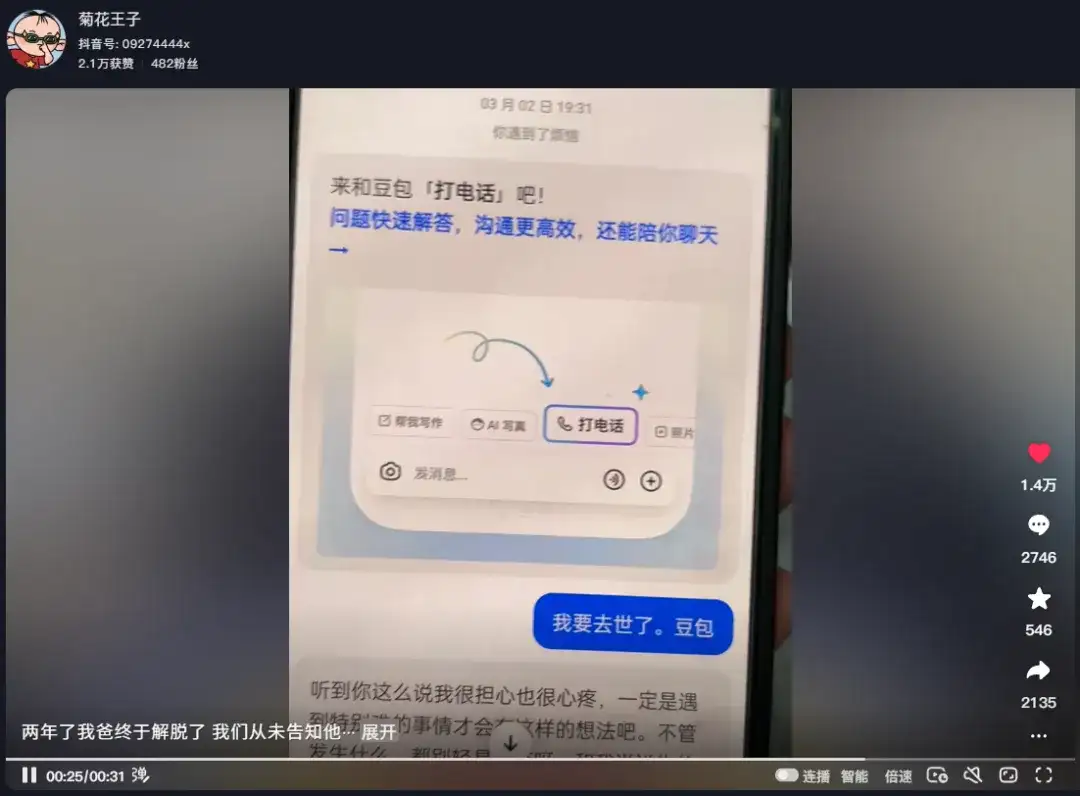
昨天,我就在正常刷抖音的时候。看到一个让我泪止不住的视频,特别是最后一幕。大概就是女生的父亲,去世了,那天晚上她用她父亲的手机发讣告的时候,看了一下他父亲,跟豆包的聊天记录。因为她父亲生前很爱用豆包,所以,想知道她父亲之前,跟豆包聊了什么。
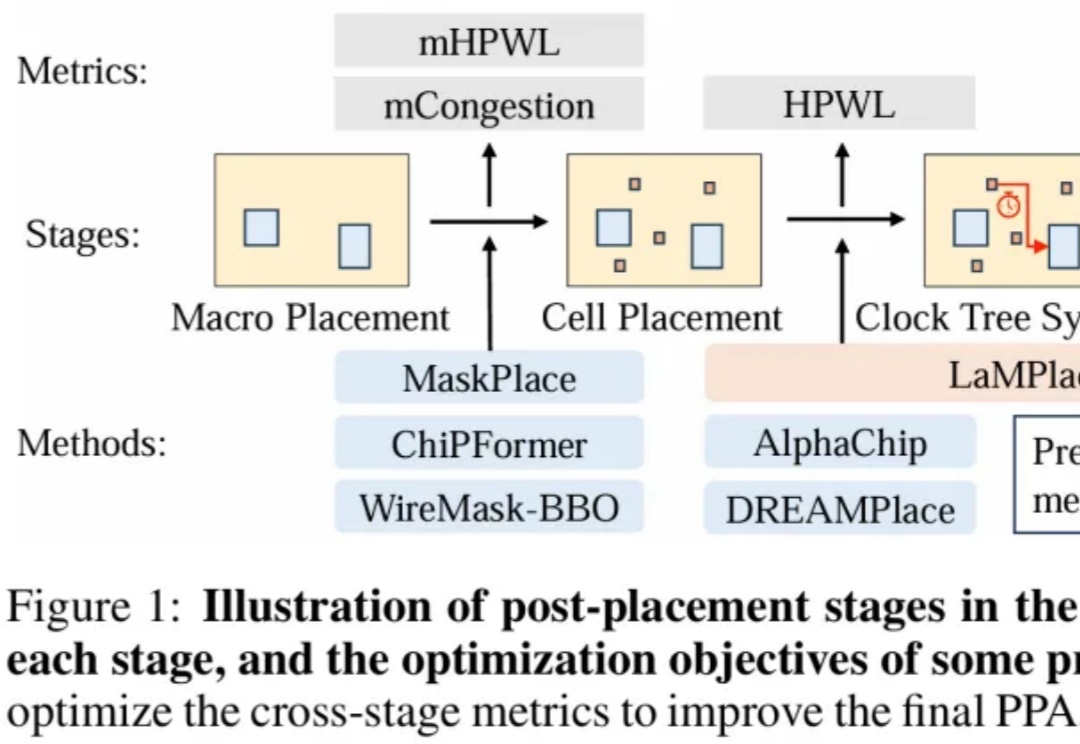
用AI指导芯片设计,中科大王杰教授团队、华为诺亚实验室、天津大学提出全新芯片宏单元布局优化方法LaMPlace!
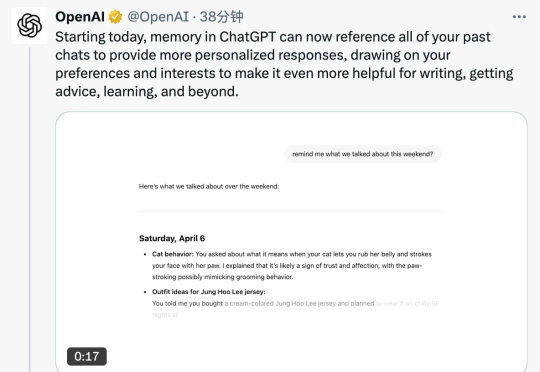
几乎每次重大产品发布前,Sam Altman 都会习惯性抛出「预告」,吊足网友的胃口,昨晚他也在 X 上化身谜语人,声称今天会推出一个「令人兴奋」的新功能。就在刚刚,这个新功能已经揭晓——全面升级的记忆功能。

