


字节视频基础大模型发布!单GPU就可生成1080P,蒋路领衔Seed视频团队曝光
字节视频基础大模型发布!单GPU就可生成1080P,蒋路领衔Seed视频团队曝光字节Seed团队视频生成基础模型,来了。
来自主题:
AI资讯
8310 点击 2025-04-15 15:17
 搜索
搜索
字节Seed团队视频生成基础模型,来了。
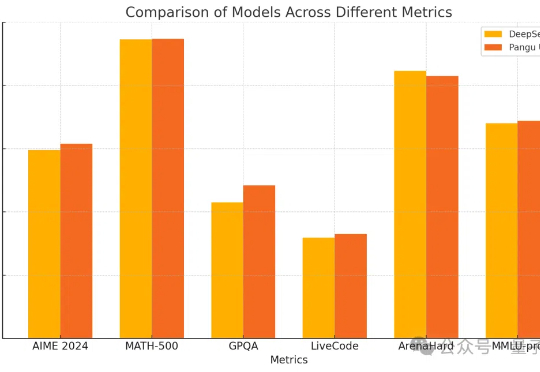
密集模型的推理能力也能和DeepSeek-R1掰手腕了?
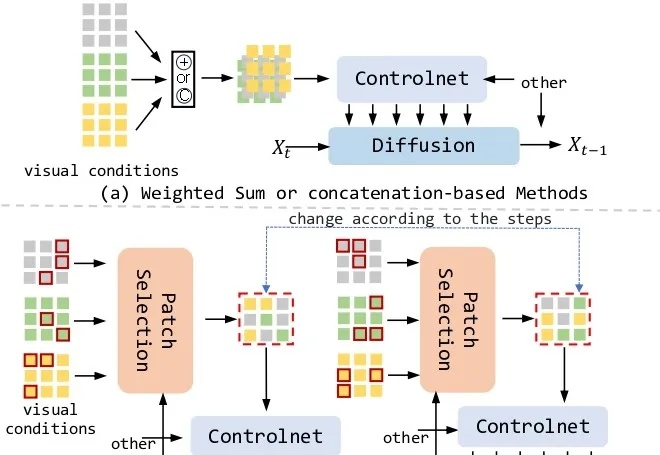
文生图新架构来了!
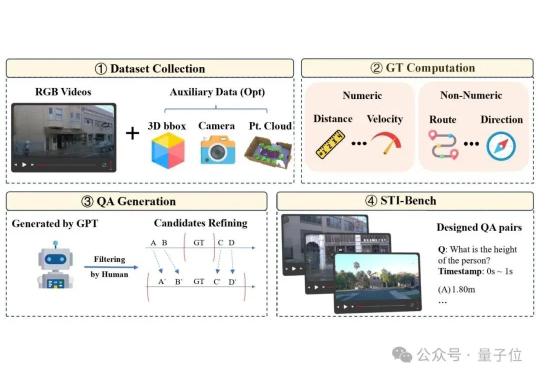
多模态大语言模型(MLLM)在具身智能和自动驾驶“端到端”方案中的应用日益增多,但它们真的准备好理解复杂的物理世界了吗?

移动GUI自动化智能体V-Droid采用「验证器驱动」架构,通过离散化动作空间并利用LLM评估候选动作,实现了高效决策。在AndroidWorld等多个基准测试中任务成功率分别达到59.5%、38.3%和49%,决策延迟仅0.7秒,接近实时响应。

Google Classroom 推出了一项新的人工智能驱动功能,旨在帮助教师生成测验题目的 AI 功能。该工具于周一上线,允许教育工作者基于特定文本输入创建一系列问题。
我们中的许多人已经在 Product Hunt 上发布了一段时间,越来越多的人开始质疑那里的受众是否真实,toB的产品是否仍然值得在他们的平台上发布。
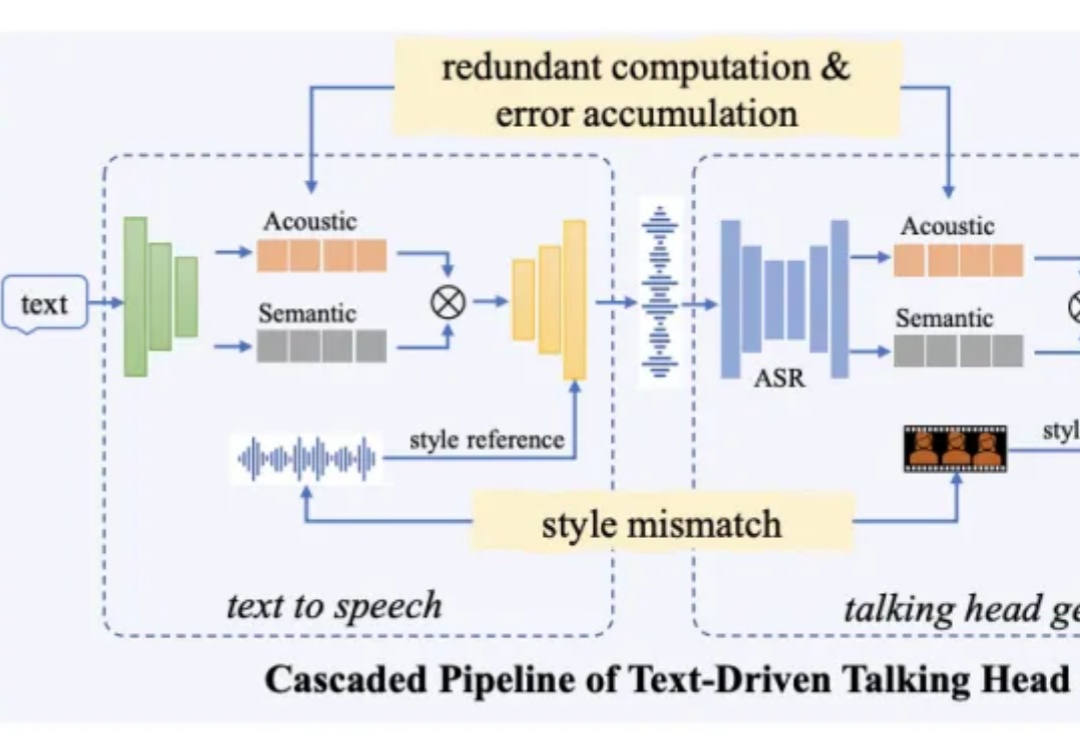
近日,阿里通义实验室推出了全新数字人视频生成大模型 OmniTalker,只需上传一段参考视频,不仅能学会视频中人物的表情和声音,还能模仿说话风格。相比传统的数字人生产流程,该方法能够有效降低制作成本,提高生成内容的真实感和互动体验,满足更广泛的应用需求。目前该项目已在魔搭社区、HuggingFace 开放体验入口,并提供了十多个模板,所有人可以直接免费使用。
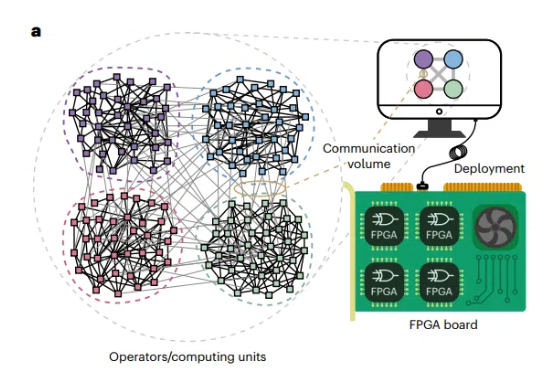
组合优化问题(COPs)在科学和工业领域无处不在,从物流调度到芯片设计,从社交网络分析到人工智能算法,其高效求解一直是研究热点。
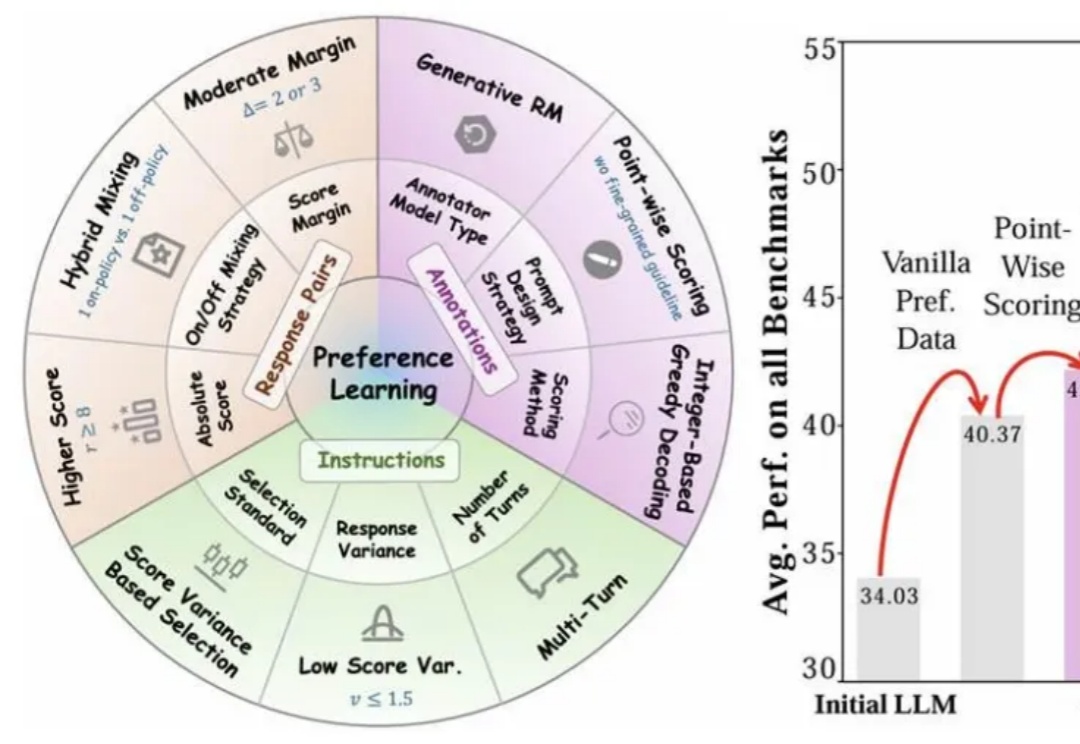
近年来,大语言模型(LLMs)的对齐研究成为人工智能领域的核心挑战之一,而偏好数据集的质量直接决定了对齐的效果。无论是通过人类反馈的强化学习(RLHF),还是基于「RL-Free」的各类直接偏好优化方法(例如 DPO),都离不开高质量偏好数据集的构建。
今天凌晨,OpenAI 的新系列模型 GPT-4.1 如约而至。

智谱将开源 32B/9B 系列 GLM 模型,涵盖基座、推理、沉思模型,均遵循 MIT 许可协议。该系列模型现已通过全新平台 Z.ai 免费开放体验,并已同步上线智谱 MaaS 平台。
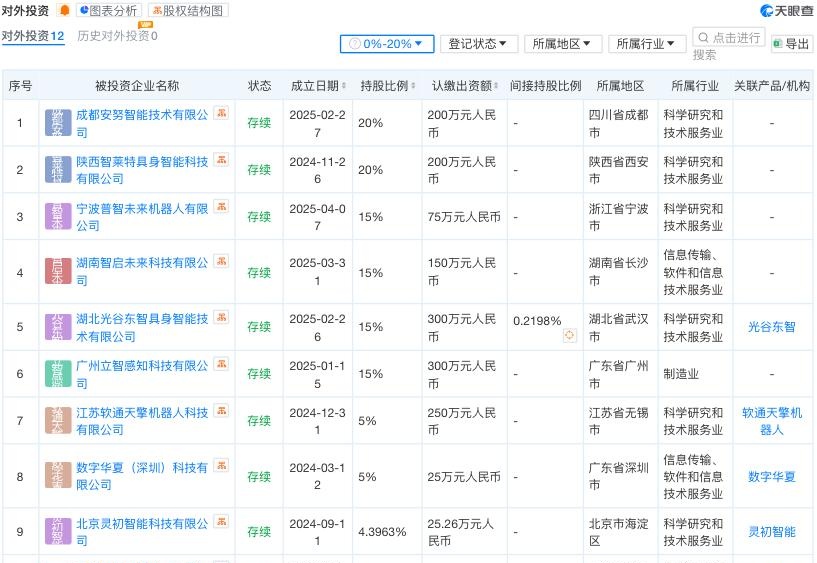
将资源和资金用在产业链投资上,“物尽其用、财尽其力”。
一切为了「多终端一致体验」和「用户数据闭环」。

谁说世界不需要文科生?

就在刚刚,智谱一口气上线并开源了三大类最新的GLM模型:沉思模型GLM-Z1-Rumination 推理模型GLM-Z1-Air 基座模型GLM-4-Air-0414
当下技术的水平还不足以支撑AI直接生成游戏,一步一个脚印才是正道。

虽然扩散模型在视频生成领域展现出了卓越的性能,但是视频扩散模型通常需要大量的推理步骤对高斯噪声进行去噪才能生成一个视频。这个过程既耗时又耗计算资源。例如,HunyuanVideo [1] 需要 3234 秒才能在单张 A100 上生成 5 秒、720×1280、24fps 的视频。
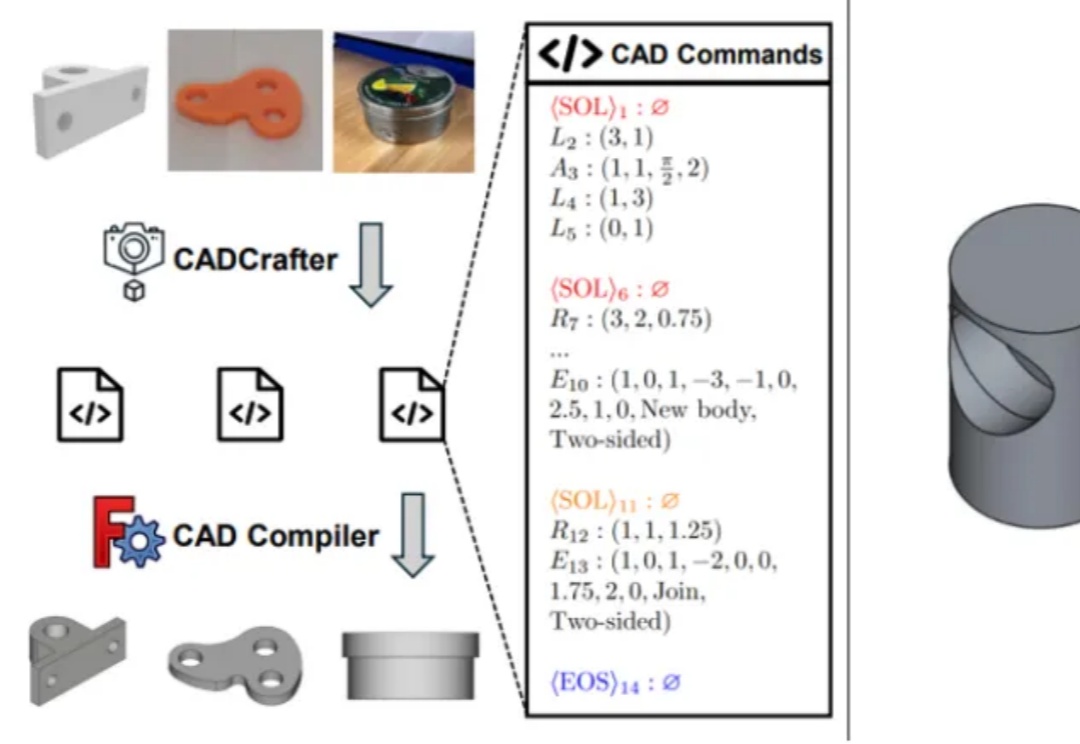
单张图直接就能生成可编辑的CAD工程文件!
重视前沿技术敏感度,编程能力成硬通货

开发Agent的工程师们都曾面临同一个棘手问题:当任务步骤增多,你的Agent就像患上"数字健忘症",忘记之前做过什么,无法处理用户的修改请求,甚至在多轮对话中迷失自我。不仅用户体验受损,token开销也居高不下。TME树状记忆引擎通过结构化状态管理方案,彻底解决了这一痛点,让你的Agent像拥有完美记忆力的助手,在复杂任务中游刃有余,同时将token消耗降低26%。

诺奖得主Demis Hassabis表示,通过AI,DeepMind团队在一年里,完成了10亿年的博士研究时间!10亿年的科学探索被压缩到了一年之内,或许这才代表了AI技术的最高使命。

书接上回,用几块3000元显卡作为加速主力的一体机,就能跑通671B的DeepSeek。

人类智能并非通用智能。

“AI是一次改变我们所知一切的历史性机会。”美国当地时间2025年4月10日,全球电商平台亚马逊CEO安迪·贾西(Andy Jassy)在发布2024年度致股东信时,不遗余力地盛赞AI。

它是永远再砍一刀的诱惑,它是便宜货的天堂,它是亿万用户心甘情愿走入的折扣迷宫。在一个平常的夜晚,正当我又一次囤积便宜日用品时,拼多多的算法推荐开始发力,一坨坨带有AI字样的商品在我的购物首页扑面而来——有AI鼠标,外形像苍蝇脑壳;

拜时代所赐,中国最现代的猪圈早已进化成“楼房养猪”这种集约化、规模化养殖的新物种,同时也越来越科技化,突出表现在AI技术的活用上。咱们这个春天里的第一口鲜,没准儿就是一块“AI猪肉”

OpenAI重磅发布的GPT-4.1系列模型,带来了编程、指令跟随和长上下文处理能力的全面飞跃!由中科大校友Jiahui Yu领衔的团队打造。与此同时,备受争议的GPT-4.5将在三个月后停用,GPT-4.1 nano则以最小、最快、最便宜的姿态强势登场。

最近,Netflix 正在悄悄测试一项黑科技功能——由 ChatGPT 背后的 OpenAI 提供支持的智能搜索服务。这不仅仅是搜索条那么简单,它可能会彻底改变你跟内容平台“对话”的方式。

刚刚,Gemini 2.5 Pro编程登顶,6美元性价比碾压Claude 3.7 Sonnet。不仅如此,谷歌还暗藏着更强的编程模型Dragontail,这次是要彻底翻盘了。

