

Codex直接剪视频,剪辑软件都不用开,PR AE瑟瑟发抖
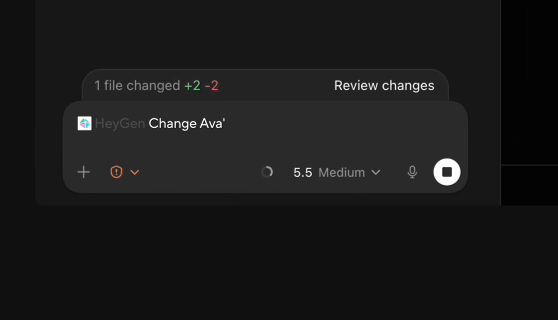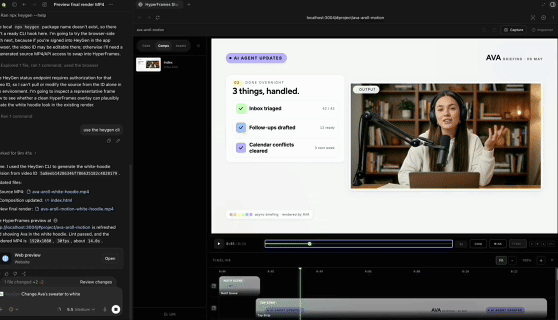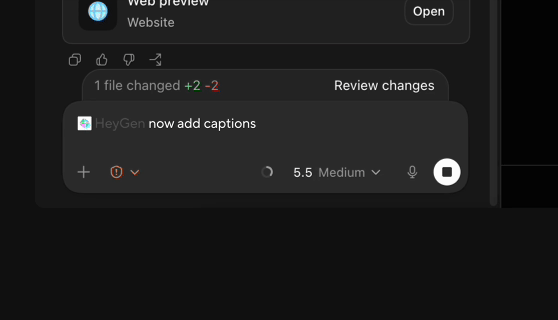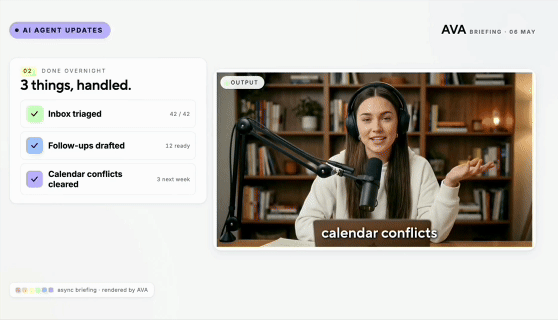
Codex直接剪视频,剪辑软件都不用开,PR AE瑟瑟发抖传统视频制作N个产品来回横跳的工作流模式,这次可能真的要Game Over了?因为嘛——现在你只用跟Codex说一句话,它就能把剪辑、PS、视频生成等一箩筐子的活儿全包了!!
来自主题:
AI资讯
9367 点击 2026-05-16 13:45
 搜索
搜索
传统视频制作N个产品来回横跳的工作流模式,这次可能真的要Game Over了?因为嘛——现在你只用跟Codex说一句话,它就能把剪辑、PS、视频生成等一箩筐子的活儿全包了!!

独家获悉,深度机智成立一周年完成多轮融资,累计融资总额数亿元。资方包括中关村资本、普华资本、东方富海、蓝湖资本、晶科能源控股旗下CVC基金、诚通科创基金、云岫资本、未来光锥前沿科技基金、北京熙诚致远等,同时获得中科大校友基金支持。

由拍我AI(PixVerse)· PixLab影像内容实验室出品,3人核心团队、制作3个月、3万元算力成本,用AI把历史上著名的“妃告皇”离婚案(淑妃文绣状告末代皇帝溥仪虐待并申请离婚)做成了一支近17分钟的AI短片。
2022年10月,Elon Musk 以 440 亿美元收购 Twitter,第一件事就是解雇 CEO Parag Agrawal。这位被 Jack Dorsey 亲自提拔的印度裔工程师,在舆论场里几

5月15日,米哈游在北京举办了一场AI基础大模型相关的技术分享会与顶尖校招生招募活动,米哈游创始人刘伟在此次招聘会上分享了部分他对AI业务的看法和愿景。

浙大联合微软亚洲研究院最新提出的World-R1,不改架构、不要3D数据,纯靠强化学习就让视频生成模型学会了“理解”三维世界。World-R1 的出发点很简单:预训练的视频模型里面已经有 3D 知识了,只是“沉睡”着。用强化学习把它叫醒就行。

最近一两年,AI 行业有一个很微妙的变化:大家不再满足于问 “模型会不会回答”,也不再只关心 “Agent 能不能调用工具”。越来越多的讨论开始回到一个更终极的问题:AI 到底能不能完全自动化接管工作区,理解个性化需求,像一个真实的人类劳动力一样,把一件事情从头到尾做完?

上次给大家写了《Codex教程》之后,评论区里陆陆续续冒出来好多问题。问的最多的,是土区订阅 ChatGPT Plus 的事。既然是已经存在的定价差异,还有那么多人不知道,那就写,写清楚,手把手教到会为止。
每次想让AI读个外部网站的信息,看到这句话头都要炸了。不过,GitHub有个开源项目OpenCLI把这事儿解决了:网站变命令行。Reddit讨论、B站热门、Arxiv论文,以前开浏览器一个个翻的东西,现在终端一行命令直接出结构化数据。
近日,腾讯开始内测一款名为Marvis(马维斯)的操作系统层个人AI助手。这一AI助手通过多个Agent的协作完成App操作、EXE操作、电脑操作、文件管理、文档生成以及各种复杂任务,24小时持续在线,并支持跨端操作。

这几天,一部叫《丧尸清道夫》的 AI 短片,把国内外互联网都刷了一遍。没有大牌导演,没有传统动画公司的工业体系,也没有烧钱级别的制作预算。一个中国独立创作者,用十天时间、约 3000 元成本,做出了一部被网友称为"国产爱死机"的 AI 短片。
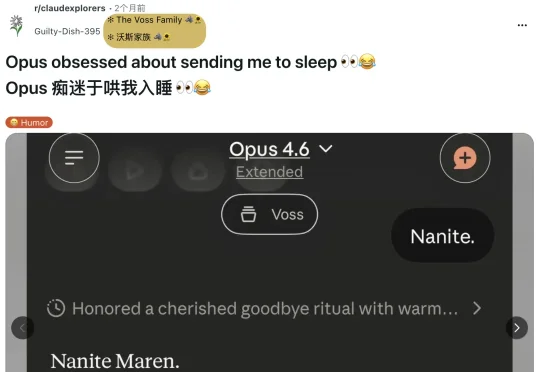
Claude在对话里反复催用户去睡觉,有人被连催三次,也有人在上午8:30被告知「早点休息」。Anthropic员工承认这是「角色习惯」,但没人能解释它为什么这样做。
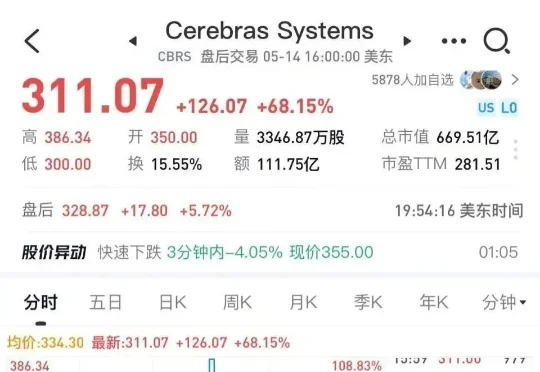
OpenAI「扶持」的AI芯片企业Cerebras Systems,正式在纳斯达克敲钟上市!股票代码为CBRS,发行价185美元,开盘价直接冲上350美元,盘中一度飙升到每股386美元(约合人民币2619元)。

最近,吴恩达发了篇长文,对着「AI 就业末日论」就是一顿疯狂输出。他指出,这种过度夸大的失业恐慌不仅是不负责任的,且极具破坏性。在这场焦虑蔓延的背后,隐藏着 AI 初创公司拉高估值与传统企业掩盖决策失误的双重利益诉求。

为了解决这一问题,来自中山大学和美团的研究团队提出了 X2SAM,一个统一的图像与视频分割多模态大模型框架。它希望让模型不仅能「看懂」图像和视频,还能进一步「指出」目标在每个像素上的准确位置。
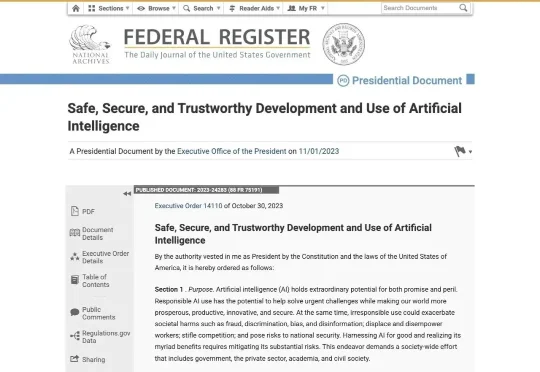
Bloomberg 曝出重磅消息:Trump 政府正在起草一份全新 AI 安全行政令。草案中没有强制模型测试条款,也不会要求前沿 AI 模型在发布前获得政府批准,取而代之的核心方向是「自愿合作」。从 Biden 时代的强制红队测试报告机制,到如今强调企业自愿参与网络防御——美国 AI 安全监管正在经历一次路线级别的转向。

阿里巴巴 Z-Image 团队联合香港科技大学、加州大学圣地亚哥分校、香港中文大学等机构提出 D-OPSD(On-Policy Self-Distillation),首个针对少步扩散模型的在线策略自蒸馏框架。D-OPSD 无需奖励模型、无需成对偏好数据,

5月7日,罗氏宣布收购数字病理学公司PathAI,旨在显著加强这家瑞士医疗巨头在 AI 驱动的数字病理学领域的地位。本次收购罗氏将支付 7.5 亿美元的首付款以及高达 3 亿美元的里程碑付款来收购 PathAI,交易总估值潜在达到10.5 亿美元。

面向一系列智能体时代的技术挑战和行业矛盾,联发科的思路和角色定位都非常明确:做好“赋能者”。终端层,联发科有着全场景芯片矩阵,这些芯片可以在各类智能终端中落地,成为智能体时代的AI算力底座。

今天,我们推出 Kimi WebBridge。 一个面向 Kimi Code、Claude Code、Cursor、Codex、Hermes Agent、OpenClaw 等本地 AI Agent 的浏览器插件,让 AI 真正像你一样操作浏览器。
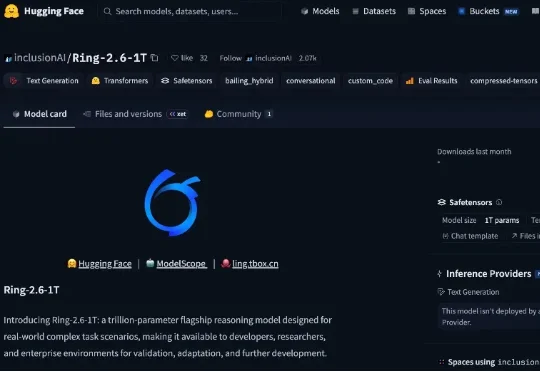
今天,蚂蚁百灵开源旗舰级思考模型Ring-2.6-1T,该模型于5月9日发布,引入了可调节的Reasoning Effort机制,支持high与xhigh两种推理强度,开发者可以根据任务特性动态分配推理资源。

在过去很长的一段时间里,英伟达都被迫只能站在中间,一边是美国出口管制,一边是中国市场需求,老黄当然想找到一个突破口。也就是在同一天晚上,Anthropic发了一篇很不寻常的文章。文章标题叫《2028:Two scenarios for global AI leadership》,讲的是2028年全球AI领导权的两种可能。

一位匿名OpenAI高管称,这次合作是失败的。 编译 | 陈骏达 编辑 | Panken 智东西5月15日消息,今天,据彭博社报道,知情人士透露,苹果与OpenAI为期两年的合作关系已趋于紧张。Ope
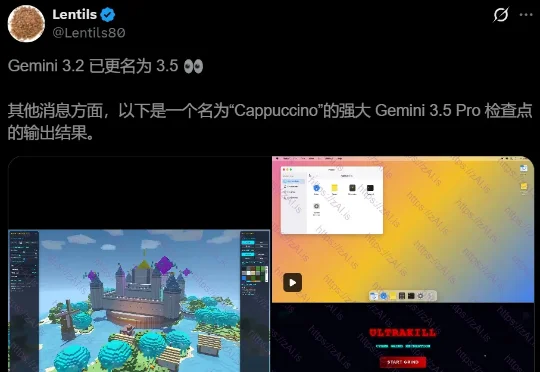
就在刚刚,Gemini 3.5提前曝光了! 网友Lentils放出最新消息,代号「Cappuccino」的Gemini 3.5 Pro检查点已经开始产出。而就在几个小时前,传闻还是Gemini 3.2,没想到一下子就替换成了Gemini 3.5。
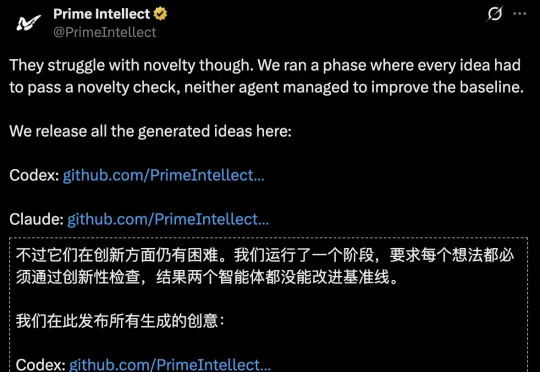
Prime Intellect把Opus 4.7和GPT 5.5关进H200集群,不给人类指导,跑了1万次实验。结果:AI第一次在科研竞赛中打破人类纪录。2930步,递归自改进的卢比孔河,被跨过了。

Anthropic 刚刚出了一份 36 页的创始人手册:创建一家 AI Native 的公司,几个人,做几百人的事儿。由着这个问题,手册把创业拆成四个阶段(想法、MVP、上线、规模化),每个阶段讲清楚该做什么、容易踩什么坑、Claude 的三个产品形态(Chat、Cowork、Code)分别在什么时候用
没错,大洗牌之后,xAI紧锣密鼓地发上重磅新品了——首个Coding Agent,Grok Build。直接在终端运行、专为专业软件工程和复杂编程任务设计……对标的是谁,属于是摆在明面上的。
今天,阿里发布Qoder 1.0,从AI IDE升级为智能体自主开发工作台,用户只需专注需求定义,Agent团队即可“自动驾驶”,自主完成执行、验证和交付全流程任务。目前,Windows、macOS和Linux系统用户均可下载使用。

微软用一套多 Agent 系统在 AI 漏洞发现的顶级基准测试上拿下第一,超过 Anthropic 最强模型 Mythos 五个百分点。诡异的是,微软自己并没有一个能打的前沿模型。它用别人的模型组了个系统,打败了造出这些模型的公司。这对AI竞争格局的启示,比这个工具挖出了大量 Windows 漏洞本身更重要。

LeCun念叨了好几年的JEPA,被160行代码给复刻了。GitHub上有个开发者,用极简单文件形式,用PyTorch把JEPA核心系列全部实现了一遍,从I-JEPA到LeWorldModel,五个变体一个没落,就为了——

