


Manus 对谈 YouTube 联创陈士骏:两代创业者聊 AI 创业和长期主义
Manus 对谈 YouTube 联创陈士骏:两代创业者聊 AI 创业和长期主义Manus 上线几天后,联合创始人、首席科学家 Peak(季逸超)在 X 里收到了 Steve Chen 的一条私信。据 Peak 回忆,他整个人都跳了起来。
来自主题:
AI资讯
9439 点击 2025-07-09 11:19
 搜索
搜索
Manus 上线几天后,联合创始人、首席科学家 Peak(季逸超)在 X 里收到了 Steve Chen 的一条私信。据 Peak 回忆,他整个人都跳了起来。

大数据已经能闻出AI味儿了!最近,一份席卷生物医学圈的报告发出警告:如果你论文里高频出现delves、underscores等454个特定词汇,就要小心了——这很可能就是AI留下的「指纹」。

2025年的AI编程赛道已非蓝海——从OpenAI Codex、Claude Code到阿里的通义灵码、字节的Trae,全球科技巨头正争相将AI深度嵌入开发者工作流,将其视为核心场景的关键入口。
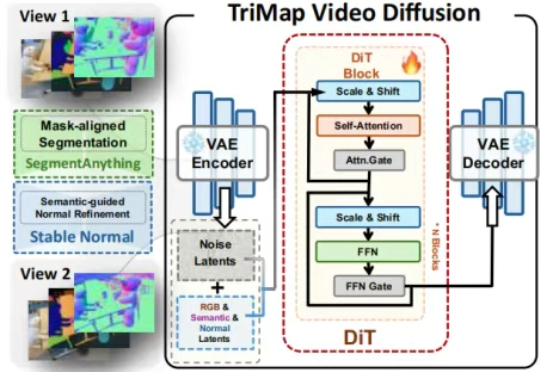
最少只用2张图,AI就能像人类一样理解3D空间了。ICCV 2025最新中稿的LangScene-X:以全新的生成式框架,仅用稀疏视图(最少只用2张图像)就能构建可泛化的3D语言嵌入场景,对比传统方法如NeRF,通常需要20个视角。

“同时做大脑和本体,看起来可能会非常难,但对我来说,因为我都能做,所以这是一个自然选择。”

美国教师联盟与美国教师联合会、微软、OpenAI和Anthropic合作,耗资2300万美元成立“国家人工智能教学学院”;
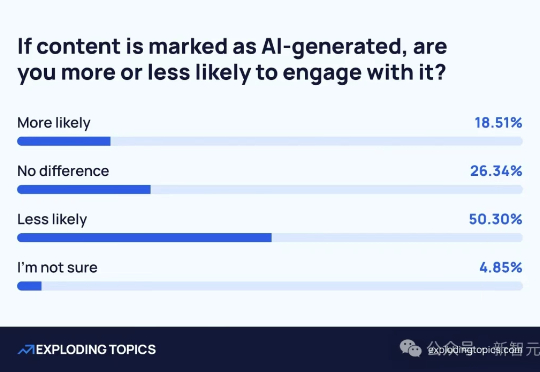
最新调查称,全球仅有8%的人愿意为AI买单!然而,科技巨头们正以「创新」之名,将AI硬塞进日常软件中。一位外国小哥Ted Gioia发文吐槽自己被微软AI全家桶绑架,每月不得不花冤枉钱。

在多模态大语言模型(MLLMs)应用日益多元化的今天,对模型深度理解和分析人类意图的需求愈发迫切。尽管强化学习(RL)在增强大语言模型(LLMs)的推理能力方面已展现出巨大潜力,但将其有效应用于复杂的多模态数据和格式仍面临诸多挑战。

提起AI游戏,大多普通玩家所能想到的,可能是预设好的可对话“Chatbot”AI NPC、在对抗游戏中“更聪明”的人机队友或敌人,又或是让AI充当类似GM的职能,引导玩家推进游戏流程。
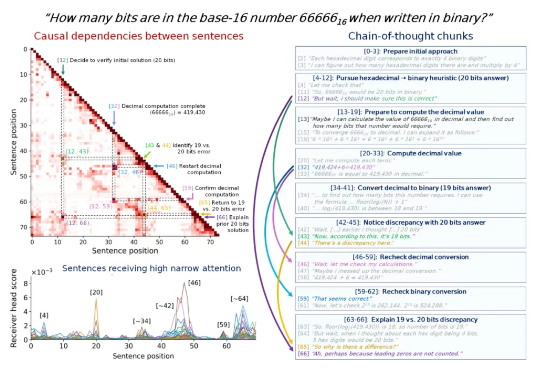
思维链里的步骤很重要,但有些步骤比其他步骤更重要,尤其是在一些比较长的思维链中。 找出这些步骤,我们就可以更深入地理解 LLM 的内部推理机制,从而提高模型的可解释性、可调试性和安全性。
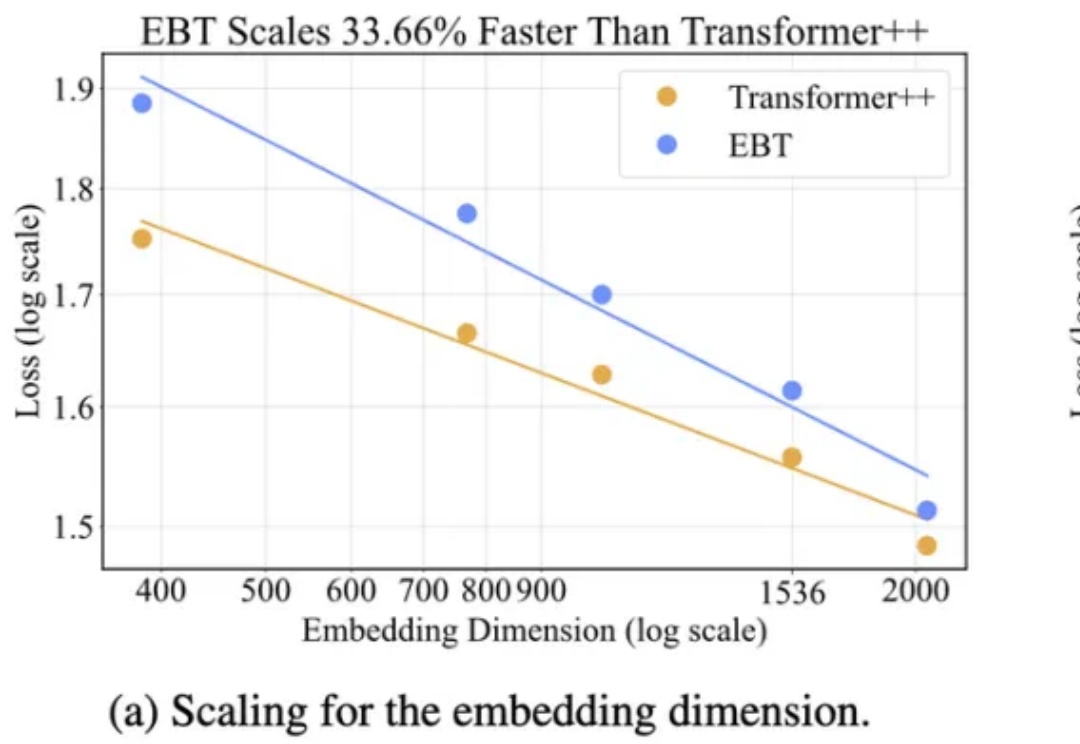
AI无需监督就能学习思考?

欧莱雅与大宁集团美创静界签署合作备忘录,共同支持大学生用科技赋能美妆应用场景

即使有一颗大隐隐于市的心,成立第八年的云深处,终究在今天具身智能的浪潮下,被推到了舞台中央。
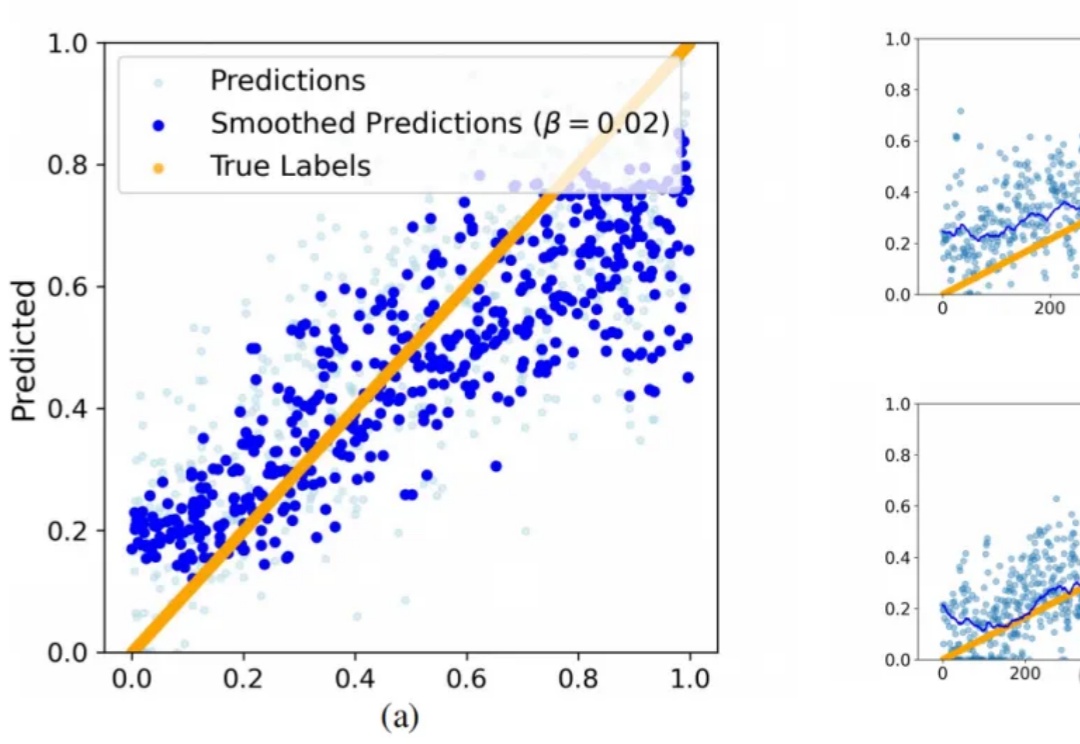
DeepSeek推理要详细还是要迅速,现在可以自己选了?
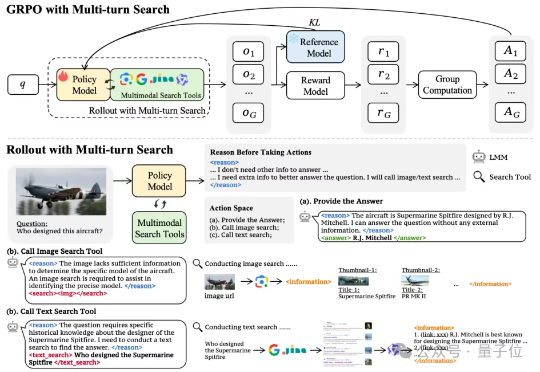
多模态模型学会“按需搜索”!字节&NTU最新研究,优化多模态模型搜索策略——通过搭建网络搜索工具、构建多模态搜索数据集以及涉及简单有效的奖励机制,首次尝试基于端到端强化学习的多模态模型自主搜索训练。
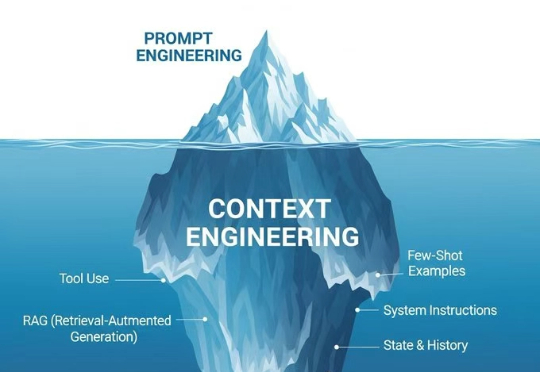
就像是播放音乐,Prompt Engineering是在调音响的音量,那Context Engineering就是在设计整个音响系统,从音源、功放、音箱到房间声学,每个环节都要精心设计。Context Engineering本质上是设计和优化AI模型整个上下文窗口的工程学科。这不只是一个技术升级,更像是思维模式的根本转变。

当ChatGPT横空出世时,它以空前的方式将AI 议题推至公众视野的核心。然而,同时迸发的诸多讨论却固着于恐惧、忧虑与批判情绪。

7月8日消息,谷歌智能体业务主管奥马尔·沙姆斯(Omar Shams)近日做客播客节目《Manifold》,接受了密歇根州立大学计算数学教授、大模型应用开发商Superfocus.ai创始人Steve Hsu的专访。沙姆斯曾创办AI初创公司Mutable,后被谷歌收购。

美国加州北区法院上周48小时内对Anthropic和Meta两起AI版权案作出简易判决。两案均承认AI训练属"合理使用",但对"转换性使用"认定、"市场损害"评估及盗版素材使用等关键法律问题存在显著分歧,暴露版权法应对AI技术的司法裂痕。

就在刚刚,据《连线》杂志报道,OpenAI 总裁 Greg Brockman 本周二在公司 Slack 群里宣布从特斯拉、xAI 和 Meta 挖来四位硬核工程师,并将加入 OpenAI 的扩展团队。值得一提的是,Dalton 和 Ruddarraju 之前也都曾在 Robinhood 工作过。
「哈喽,可以听到吗?」北京时间上午 10 点,大洋彼岸的 Pokee.ai 创始人朱哲清接通了我们的连线电话,此刻他正位于美国西海岸,当地时间为前一日晚上 7 点。「哈喽,可以听到吗?」北京时间上午 10 点,大洋彼岸的 Pokee.ai 创始人朱哲清接通了我们的连线电话,此刻他正位于美国西海岸,当地时间为前一日晚上 7 点。

Tech星球独家获悉,字节首个AI医疗助手独立App“小荷AI医生”已于近日上线,从产品定位看,这是一个健康管家,能够实现健康问题咨询和报告解读等服务。小荷AI医生最主要的功能之一就是健康咨询,覆盖疾病自查、用药参考、健康建议等众多场景,同时会主动收集用户提供的关键信息(如症状持续时间、过敏史等)。

我们独家获悉,具身智能初创公司它石智航近期完成 1.22 亿美元天使 + 轮融资。本轮融资由美团战投领投,钧山投资、碧鸿投资、国汽投资、临港科创投、赛富投资基金、建发新兴投资共同跟投。老股东线性资本、 襄禾资本等也在本轮追加投资。其中,美团的投资额约在3亿—4亿元。

《涌现NewThings》是我们关注新兴AI应用的一档新栏目,如果你也是文生图/视频、情感陪伴、Coding、智能硬件等等AI应用创业者
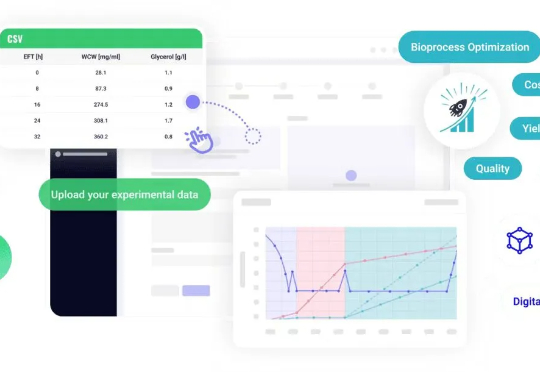
近日,以色列初创公司Algocell宣布获得 280 万美元(约合人民币2000万元)的种子前融资。

小扎就连苹果也没有放过。刚刚,苹果基础模型团队负责人Ruoming Pang被曝加入Meta,竟因苹果内部一直探索OpenAI等模型,团队士气下滑。他的离开,让苹果AI的未来更加扑朔迷离。
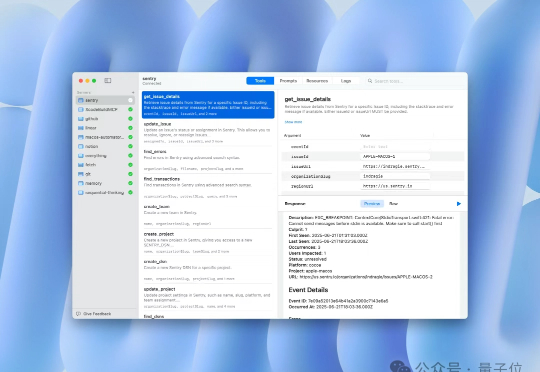
苹果开发者自曝用AI开发应用程序,Claude含量95%!事情是这样的,一位苹果开发者最新发布了一款用于调试MCP服务器的原生macOS应用Context——一款几乎完全由Claude Code构建的应用程序。

刚刚,AI制药从理论迈向实践的关键一步!DeepMind分拆公司,亮出「秘密武器」:基于AlphaFold系统研发的候选药物,已进入人体临床实验。这意味着将大幅缩短新药研发周期、降低成本,加速新药惠及患者。
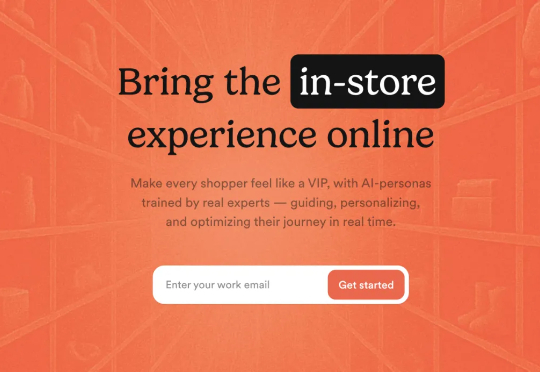
你有没有想过,为什么实体店的转化率能达到30-35%,而在线购物网站却只有可怜的1.5%?

在信息爆炸的时代,传统关键词搜索已难以满足复杂知识需求。最新研究提出Agentic Deep Research

