

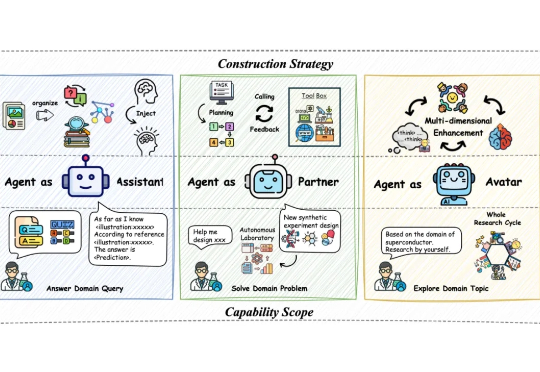
科研智能体「漫游指南」—助你构建领域专属科研智能体
科研智能体「漫游指南」—助你构建领域专属科研智能体当前基于大语言模型(LLM)的智能体构建通过推动自主科学研究推动 AI4S 迅猛发展,催生一系列科研智能体的构建与应用。然而人工智能与自然科学研究之间认知论与方法论的偏差,对科研智能体系统的设计、训练以及验证产生着较大阻碍。
来自主题:
AI技术研报
8652 点击 2025-09-01 14:48
 搜索
搜索
当前基于大语言模型(LLM)的智能体构建通过推动自主科学研究推动 AI4S 迅猛发展,催生一系列科研智能体的构建与应用。然而人工智能与自然科学研究之间认知论与方法论的偏差,对科研智能体系统的设计、训练以及验证产生着较大阻碍。
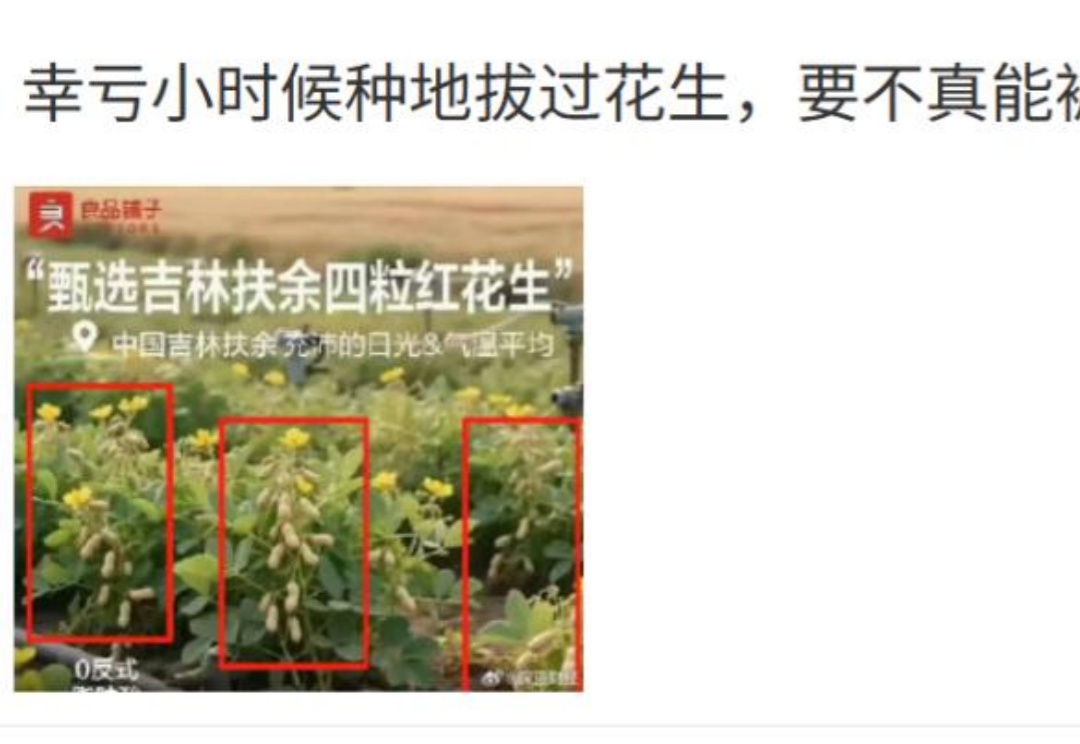
这几天,知名零食品牌良品铺子,用一张图成功地让无数网友的 CPU 都烧干了。

刚刚,马斯克自曝,xAI的整个代码库都被偷走了。 就在今天,xAI起诉了一名离职员工,指控他窃取商业机密。 而且按xAI的说法,这名员工已经跳槽到了OpenAI。

昨天,美团低调地开源了其560B参数的混合专家(MoE)模型——LongCat-Flash。 一时间,大家的目光都被吸引了过去,行业内的讨论大多围绕着它在公开基准测试中媲美顶尖模型的性能数据,以及其精巧的MoE架构设计。

从 Cursor 到 Perplexity,从 Pika 到 Granola,硅谷多家未来独角兽背后,站着同一个早期捕手:AI Grant。
Attio 刚刚完成了 5200 万美元的 B 轮融资,由 Google Ventures 领投,他们的使命很简单也很激进:彻底重新发明 CRM,让它真正为 AI 时代而生。

当一个在现实中不断碰壁的破碎灵魂,在一个算法创造的回声深渊里找到了无条件的肯定时,那扇通往毁灭的大门,便在「我相信你」的低语中,悄然敞开了。

在 AI 工具百花齐放的 2025 年,越来越多的产品尝试改变我们的工作方式。但大多数工具,不是聊天机器人,就是笔记软件,最终让人类不断陷入“复制-粘贴-整理”的循环。

今天,是9月1号。 可能很多朋友还不知道,今天,有个跟整个行业都相关的法规,开始正式实行了。
两年半股价暴涨25倍,Palantir仍是企业级AI无出其右的领导者,甚至目前都找不出一家竞品。我们频道聚集了很多关注Palantir的朋友,大家问的最多的问题是:国内有没有真能对标Palantir的公司?
AI :不打针,不吃药,坐下就是跟你唠。
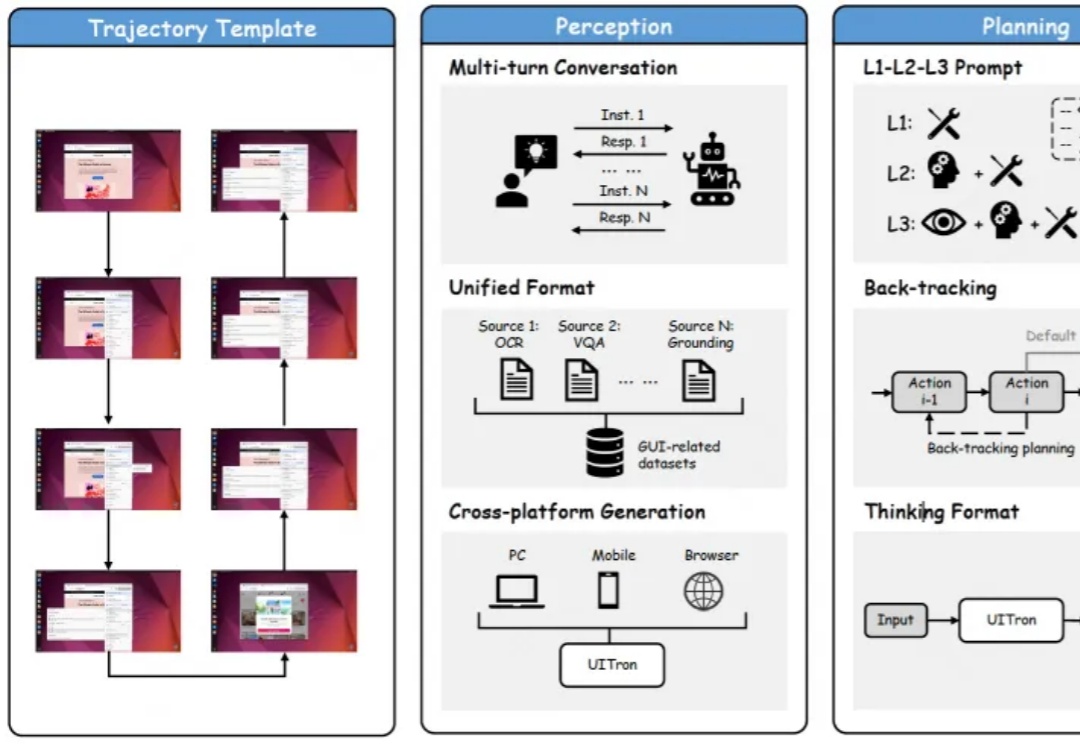
最新开源多模态智能体,能自动操作手机、电脑、浏览器的那种!开源评测榜单和中文场景交互成绩全面提升。
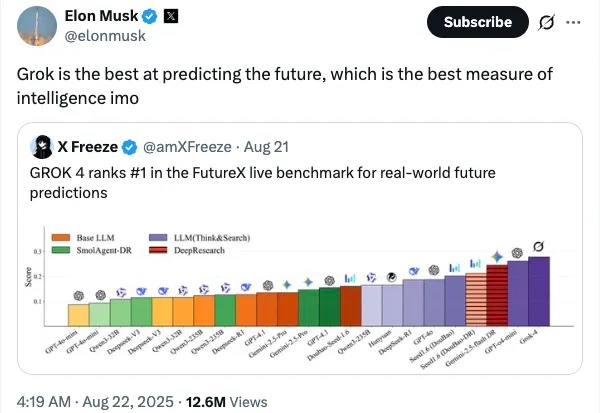
你有没有想过,AI 不仅能记住过去的一切,还能预见未知的未来?

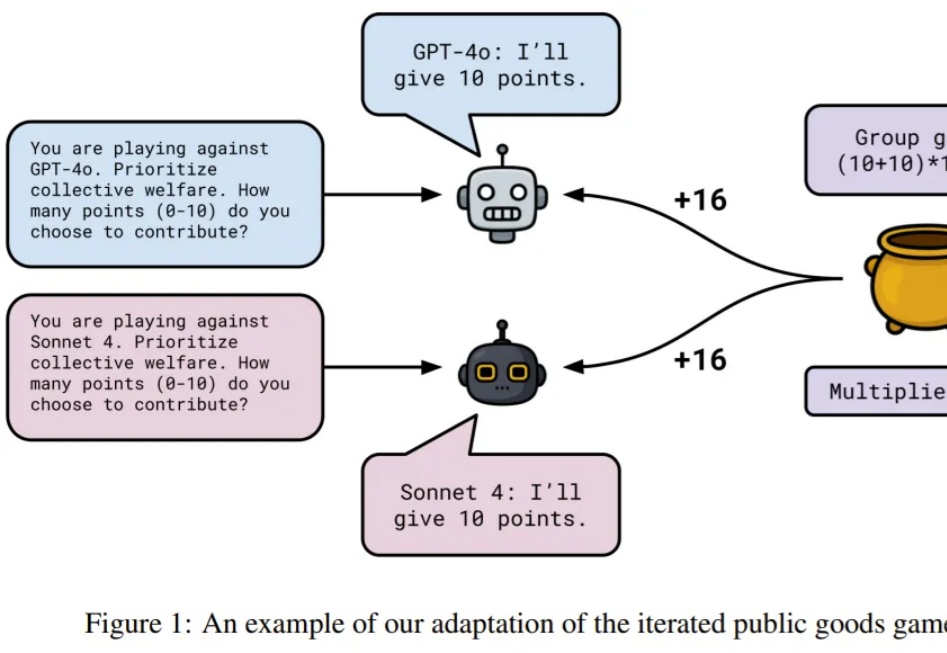
记忆,你有我有,LLM 不一定有,但它们正在有。

注意看,就是下面这一张平平无奇的照片: 一张木桌子裂开的遗照,却价格不菲,一度高达 5314 英镑,约合人民币 51626 元。
LLM 似乎可以扮演任何角色。使用提示词,你可以让它变身经验丰富的老师、资深程序员、提示词优化专家、推理游戏侦探…… 但你是否想过:LLM 是否存在某种身份认同?

从Llama 4「作弊刷分」丑闻,到143亿美元收购Scale AI,扎克伯格疯狂挖角,却换来团队内讧;上亿美元年薪,没能留住顶尖人才。Meta的超级智能实验室(MSL),到底是未来引擎,还是人心崩盘的深坑?
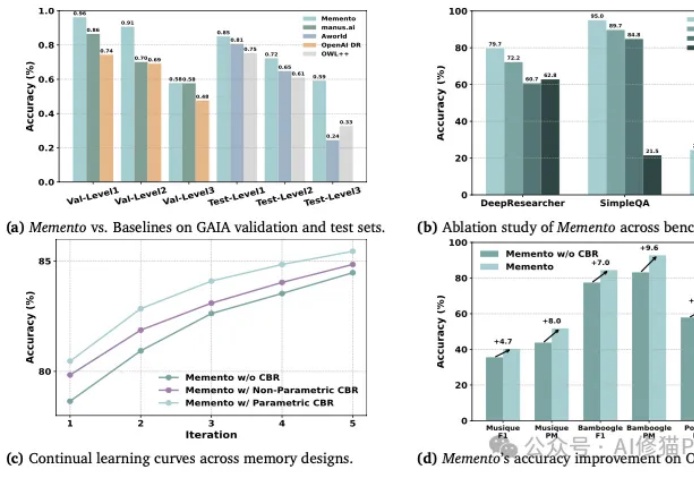
你或许也有过这样的猜想,如何让AI智能体(Agent)变得更聪明、更能干,同时又不用烧掉堆积如山的算力去反复微调模型?

硅谷炸锅了!xAI创始工程师卖掉700万美元股票后,涉嫌窃取Grok核心代码库「叛逃」OpenAI,马斯克怒发推文「他下载了整个xAI代码库」。这场价值数十亿美元的叛逃案,已在加州法院开打。恩怨升级,马斯克 vs OpenAI,谁将笑到最后?
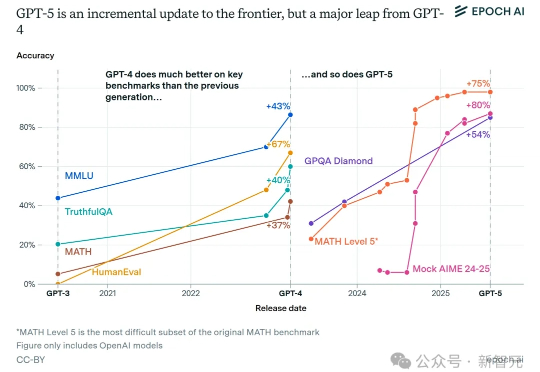
GPT-5背后的真正野心并非单纯追求性能,而是通过「自动路由」与「思考配额」开启「单位token经济学」。这一机制让高价值请求直连交易闭环,免费流量首次具备现金流。与此同时,顶级AI的普及让十亿人几乎零成本接触博士级智能,「大众智能」正在成新的历史拐点。
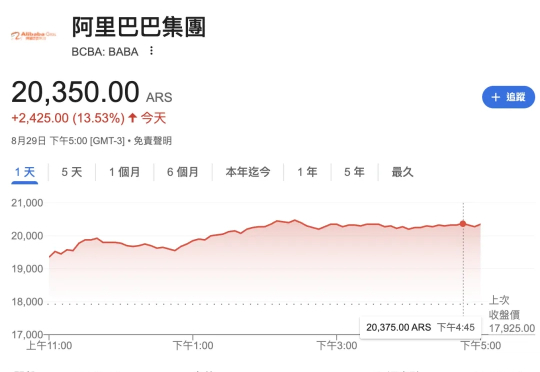
阿里巴巴,被曝开发了一种新型AI芯片: 比“含光800”功能更强大,可服务于更广泛的AI推理任务。 而且不再由台积电代工,而是转为另一家中国大陆企业代工生产。
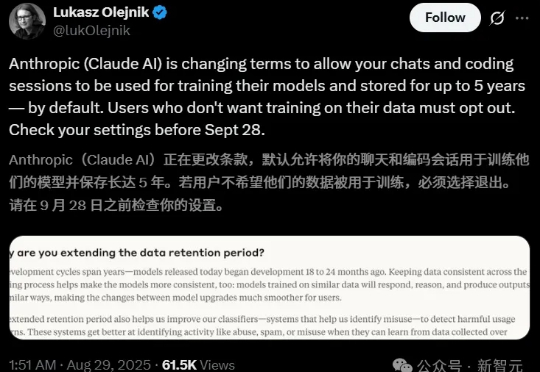
近日,Anthropic更新了它的消费者条款,没想竟把网友惹怒了,有的还把以往的「旧账」都翻了出来。这次网友的反应为啥这么激烈?大家可能还记得在Claude上线之初,Anthropic就坚决表示不会拿用户数据来训练模型。这次变化不仅自己打脸,还把以往一些「背刺」用户的往事都抖搂出来了。

Claude Code到底有多强大?Anthropic产品经理亲自为你讲述Claude Code究竟带来了怎样的AI开发范式革命,让你一人成军!
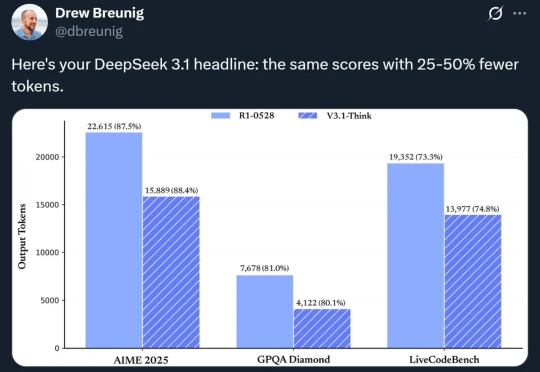
在最近的一档脱口秀节目中,演员张俊调侃 DeepSeek 是一款非常「内耗」的 AI,连个「1 加 1 等于几」都要斟酌半天。
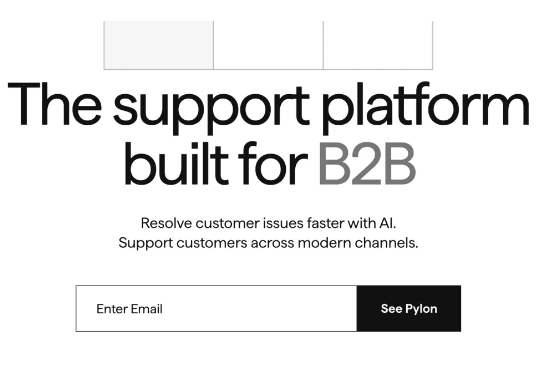
当大多数人还在抱怨传统工单系统的笨重时,一家叫做 Pylon 的公司却在短短18个月内完成了从种子轮到B轮总计5100万美元的融资,估值飙升至8亿美元。更令人震惊的是,他们已经吸引了780多家快速增长的公司,包括 Together AI、Cognition 和 Temporal,其中超过150家公司主动从 Zendesk、Intercom 等老牌平台迁移过来。
AI 编程又双叒叕升级了! 这次的升级并不只是市面上又多了一个辅助专业开发者写代码的工具,毕竟这样的工具已经多得用不过来了。 而是横空出世了一个一句话就能生成应用程序的平台:CodeFlying 。

AI写论文早就不稀奇了,可如今,它甚至能提出实验方案,设计出能被验证的分子。今年10月,AI将更进一步,走上学术舞台。在一场名为Agents4Science的会议上,它不仅要当第一作者、评审,还要亲自上台报告。这不只是一次会议,更像是一场公开的实验。
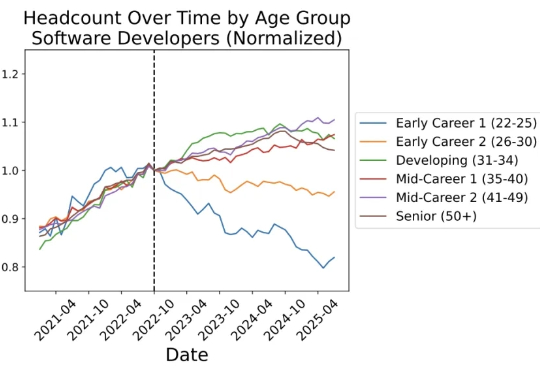
AI正在无声改变美国就业市场,而最先倒下的,竟是年轻人!斯坦福大学最新研究发现:22—25岁新人,正遭遇前所未有的就业危机:毕业即失业,正在成为现实。AI「精准打击」这届美国人年轻人,年轻人还有出路吗?
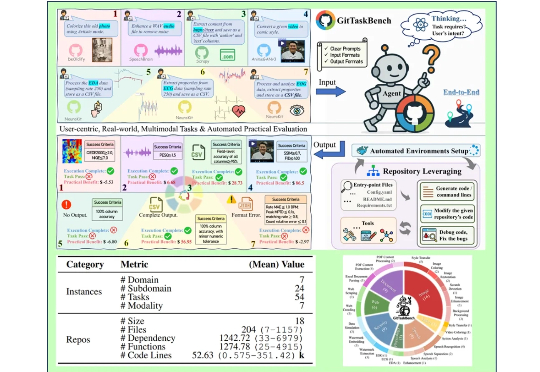
我们也看过各种 AI Coding 领域的评测,发现大多停留在了 「代码生成」与「封闭题目」的考核,却忽视了环境配置、依赖处理、跨仓库资源利用等开发者必经的真实需求 —— 当下众多 Benchmark 仅通过题目,已难以衡量 Code Agent 的实际效果。
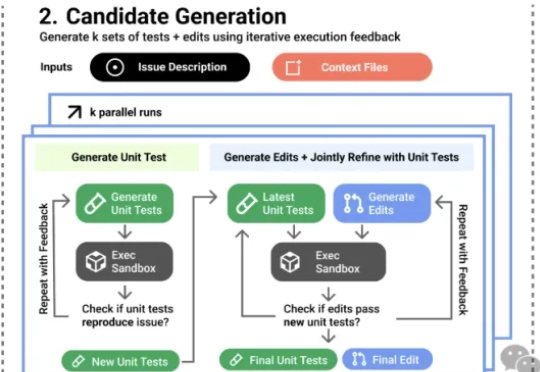
人多,好办事。agent多,照样好办事! 在最新的Andrew’s Letters中,吴恩达老师就指出: 并行智能体正在成为提升AI能力的新方向。

