


国产AI芯片看两个指标:模型覆盖+集群规模能力 | 百度智能云王雁鹏@MEET2026
国产AI芯片看两个指标:模型覆盖+集群规模能力 | 百度智能云王雁鹏@MEET2026当国产AI芯片接连发布、估值高涨之际,一个尖锐的问题依然悬在头顶:它们真的能撑起下一代万卡集群与万亿参数模型的训练吗?
来自主题:
AI资讯
10425 点击 2025-12-19 09:38
 搜索
搜索
当国产AI芯片接连发布、估值高涨之际,一个尖锐的问题依然悬在头顶:它们真的能撑起下一代万卡集群与万亿参数模型的训练吗?

我可能,刚刚成为了哈基米的儿子。 至少,AI是这么认为的。 事情是这样的。 前两天,我在小红书上闲逛,无意间用他们的AI搜索功能,搜了一下影视飓风的李四维。然后,就发现了一个神奇的AI回答。

周五凌晨,OpenAI 发布 GPT-5.2-Codex,这是迄今为止最先进的智能体编码模型,专为复杂的实际软件工程而设计。GPT-5.2-Codex 是 GPT-5.2 的升级版本,提高了指令遵循能力、对长远语境的理解能力,它针对 Codex 中的智能体编码进行了进一步优化,包括通过上下文压缩改进长期工作。

“暗涌Waves”独家获悉,AI硬件设计生成平台“指数科技”近日完成了近亿元人民币的Pre-A轮融资,由云启资本领投,誉尊资本、尚势资本跟投。而在此前的2024年,指数科技在刚成立不久、只有demo时,已完成由启赋资本和华盖资本联合领投的天使轮融资。
就在刚刚,ChatGPT 应用商店已经正式推出。

2027年落地,主攻AI推理。
继 SAM(Segment Anything Model)、SAM 3D 后,Meta 又有了新动作。

最近在网络上,你很难躲过《大东北我的家乡》的各种AI翻唱版本,男声、女声,粤语版、四川话版,爵士、布鲁斯版等等,引发一波互联网文化热潮。

科技赛道从不缺“造梦者”,但能精准击中行业痛点的“破局者”往往寥寥。
据《The Information》报道,OpenAI 正与投资者进行融资谈判,计划以 7500 亿美元的估值筹集数百亿美元资金。

谷歌正在推进一项代号为「TorchTPU」的战略行动,核心是让全球最主流的 AI 框架 PyTorch 在自家 TPU 芯片上跑得更顺畅。这项行动不仅是技术补课,更是一场商业围剿。作为 PyTorch 的掌控者,Meta 也深度参与其中,两家巨头试图联手松动英伟达的垄断地位。
前不久,在极客公园创新大会上,我们给 7 款 AI 产品策划了一个特别的「线下发布会」。

破天荒!这一次,硅谷难得没有在吵着“让AI取代程序员”。
游戏&装机党注意了!

如果你还在纠结—— “学生用 AI 写作业算不算作弊?” “学校要不要禁 ChatGPT?”

人类打字速度,竟成了制约AGI的瓶颈?近日,OpenAI Codex负责人Alexander Embiricos爆出了这一惊人观点。Embiricos还预测,2026年,当AI开始在一些领域具备自我审查能力,将触发生产力出现「曲棍球杆式」飞跃增长,并带动人类迈向AGI。

2025 年,是 AI 智能眼镜大爆发的一年。

坏了,阿里这波是冲着Sora 2去的!

今天,在 FORCE 原动力大会上,火山引擎发布豆包大模型1.8、豆包视频生成模型 Seedance 1.5 pro。经过一年多的持续升级,豆包大模型家族在多模态理解和生成能力、Agent 能力上,已位于全球第一梯队。
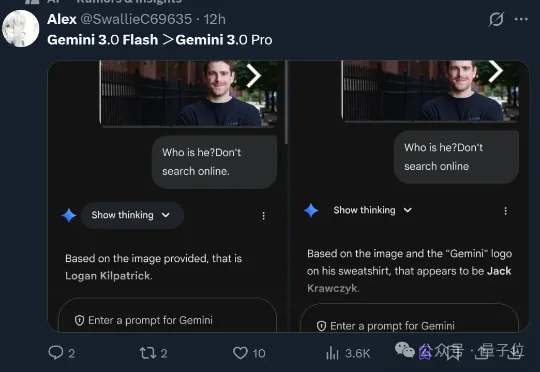
谷歌丢出Gemini 3 Flash,给AI圈示范了啥叫:小孩子才做选择题,成年人当然是全都要(doge)。一个公式来形容这款新模型:Gemini 3 Flash=Pro级智能+Flash级速度+更低价格。
可支持24帧/秒的长时流式生成。

AI 让每个人都能制作视频,但许多 AI 视频创作工具缺乏音频支持。Mirelo 正在开发能根据视频内容匹配音效的 AI 技术。

AI竞技场开始清场。

AI一键成片神器来临!今天,Vidu Agent开启全球内测,一句话复刻爆款,从广告到创意短片,分镜级可控一键短片。

OpenAI 聘请了英国前财政大臣乔治·奥斯本,领导一项与各国政府合作建设人工智能基础设施的新计划。随着各国竞相获取运行先进人工智能系统所需的数据中心和计算能力,OpenAI 选择了一位备受瞩目的政治人物来推动此事。

OpenAI最新发布的FrontierScience基准,试图用真实的博士级难题,从物理、化学、生物三个维度上考验AI。真相是残酷的:在没有唯一标准答案的科研实战中,AI作为「顶级做题家」,距离真正的科学家,还差得远。

一场投入真金白银的AI陪伴实验。
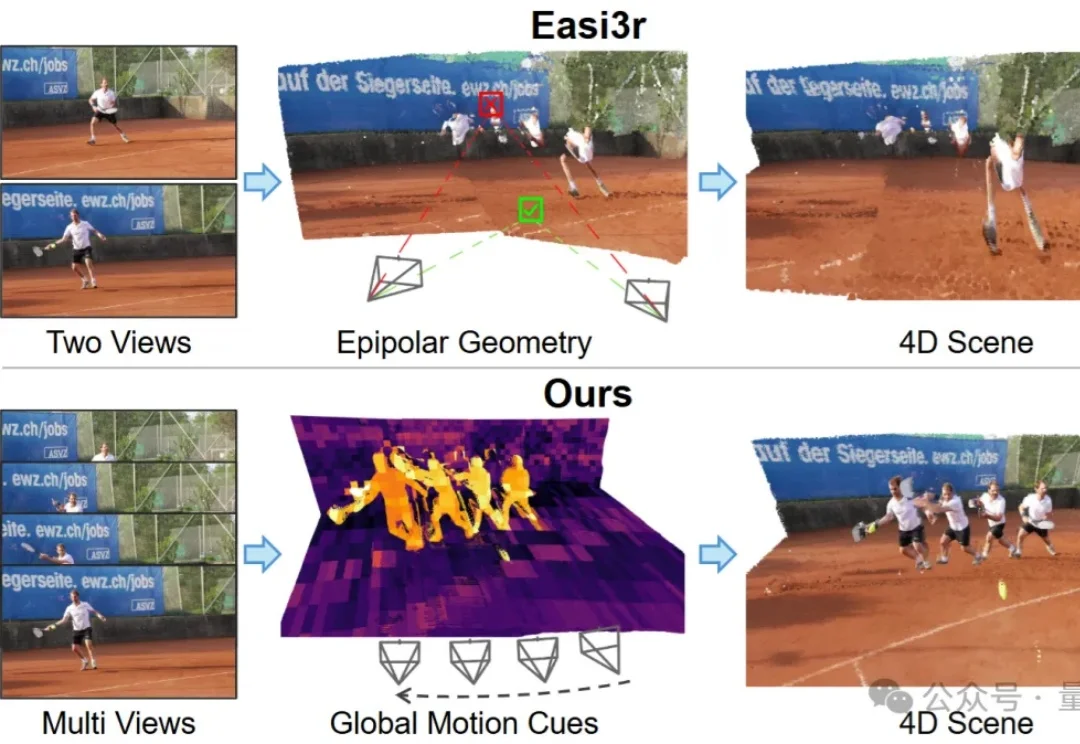
如何让针对静态场景训练的3D基础模型(3D Foundation Models),在不增加训练成本的前提下,具备处理动态4D场景的能力?

首个AI视频生成全球挑战赛来袭,袁粒、颜水成、程明明、田永鸿、Philip Torr多位大佬发起,20万大奖虚位以待!创作大神还是技术极客?两大赛道总有一个适合你,速速点击报名吧。
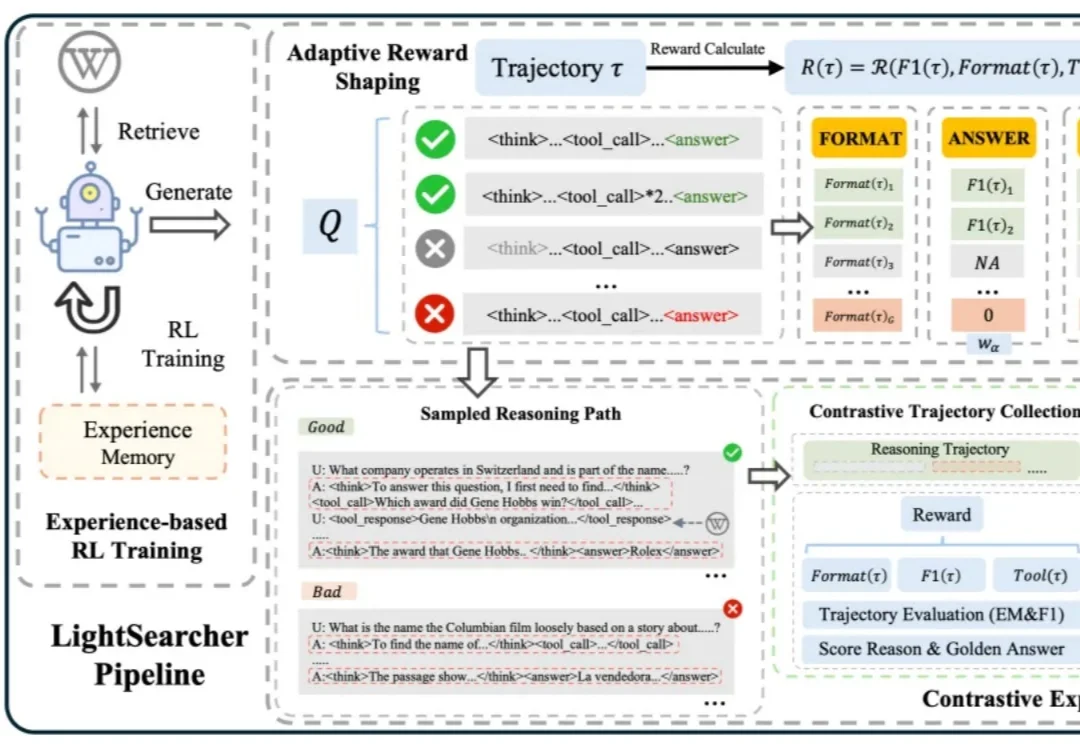
如今,以 DeepSeek-R1 为代表的深度思考大模型能够处理复杂的推理任务,而DeepSearch 作为深度思考大模型的核心搜索器,在推理过程中通过迭代调用外部搜索工具,访问参数边界之外的最新、领域特定知识,从而提升推理的深度和事实可靠性。

