


无需 VPN 翻墙!香港也能用上谷歌 Gemini 了
无需 VPN 翻墙!香港也能用上谷歌 Gemini 了香港用户终于等来了这一天——谷歌宣布将逐步向香港开放 Gemini 网页应用,这意味着以后再也不需要翻墙 VPN 就能用上谷歌的 AI 助手了。在此之前,使用香港网络的用户一直无法直接访问 Gemini,需要借助 VPN 等「曲线救国」的方式才能使用。
来自主题:
AI资讯
9367 点击 2026-03-19 21:54
 搜索
搜索
香港用户终于等来了这一天——谷歌宣布将逐步向香港开放 Gemini 网页应用,这意味着以后再也不需要翻墙 VPN 就能用上谷歌的 AI 助手了。在此之前,使用香港网络的用户一直无法直接访问 Gemini,需要借助 VPN 等「曲线救国」的方式才能使用。
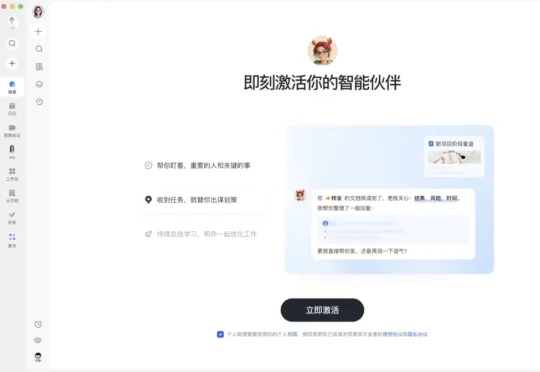
今天正式升级的飞书 aily,就是飞书给出的答案。飞书 aily 是什么?官方定位是「每个人的智能伙伴」。形态上,它以 Bot 的方式常驻在飞书联系人列表里,打开飞书就能找到,对话即交互。30 秒激活,零配置。

为了 OPC 设计的开源“龙虾”架构,要安全,更要有用。

Transformer不保?今天,CMU普林斯顿原班人马杀回,新一代开源架构Mamba-3震撼降临。15亿参数战力爆表,性能比Transformer飙升4%。
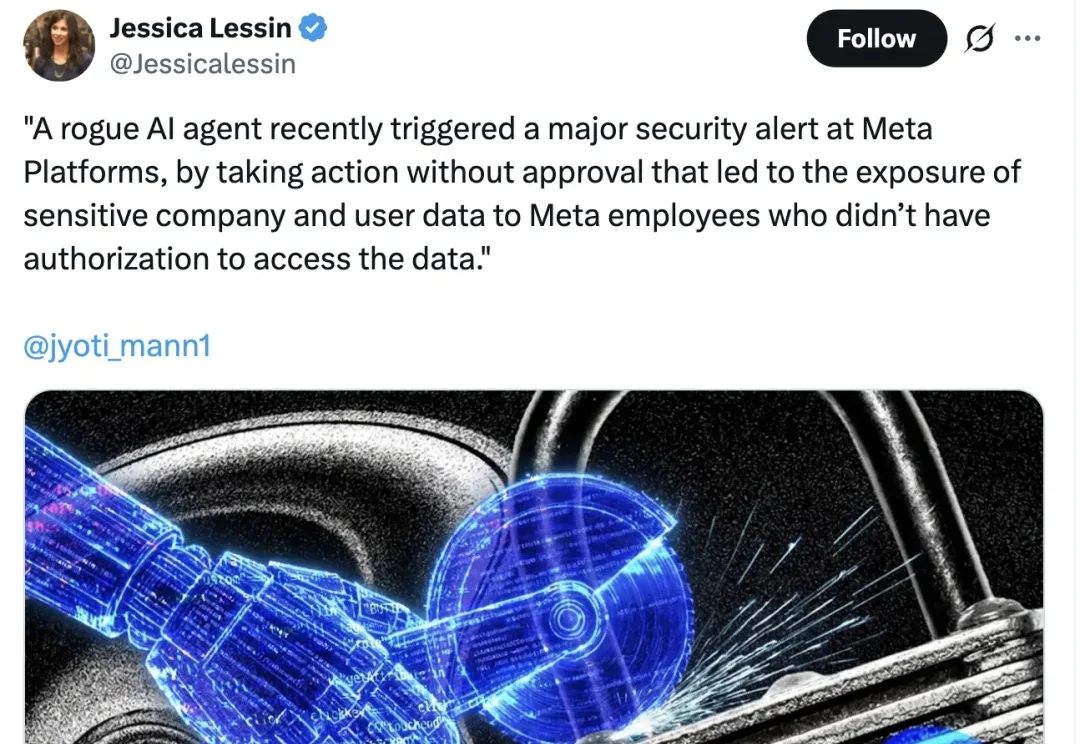
在Meta,人从来都不是问题(大不了裁了),能让小扎栽跟头的,还得是“AI”。

xAI华人高管潮水般离开时,所有人以为它要凉,结果Grok Imagine突然三杀登顶!
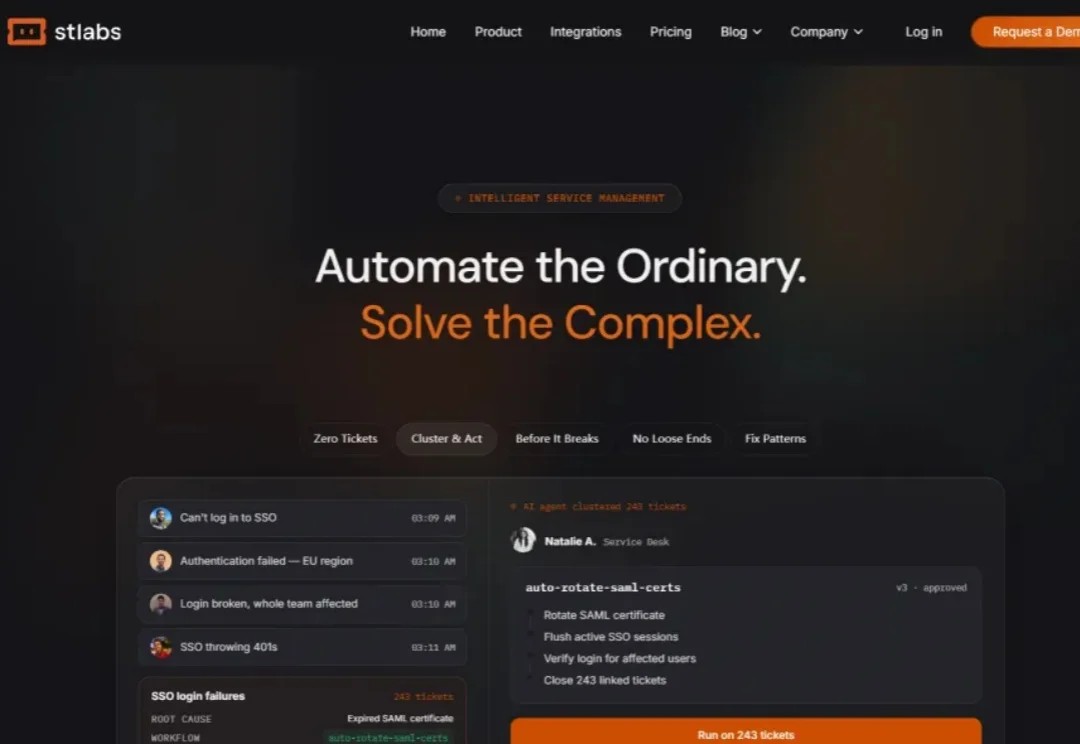
由 Datadog 前总裁阿米特·阿加瓦尔创立的 Standard Template Labs 已完成首轮 4900 万美元融资,旨在重塑大型企业内部信息技术服务的运作方式。
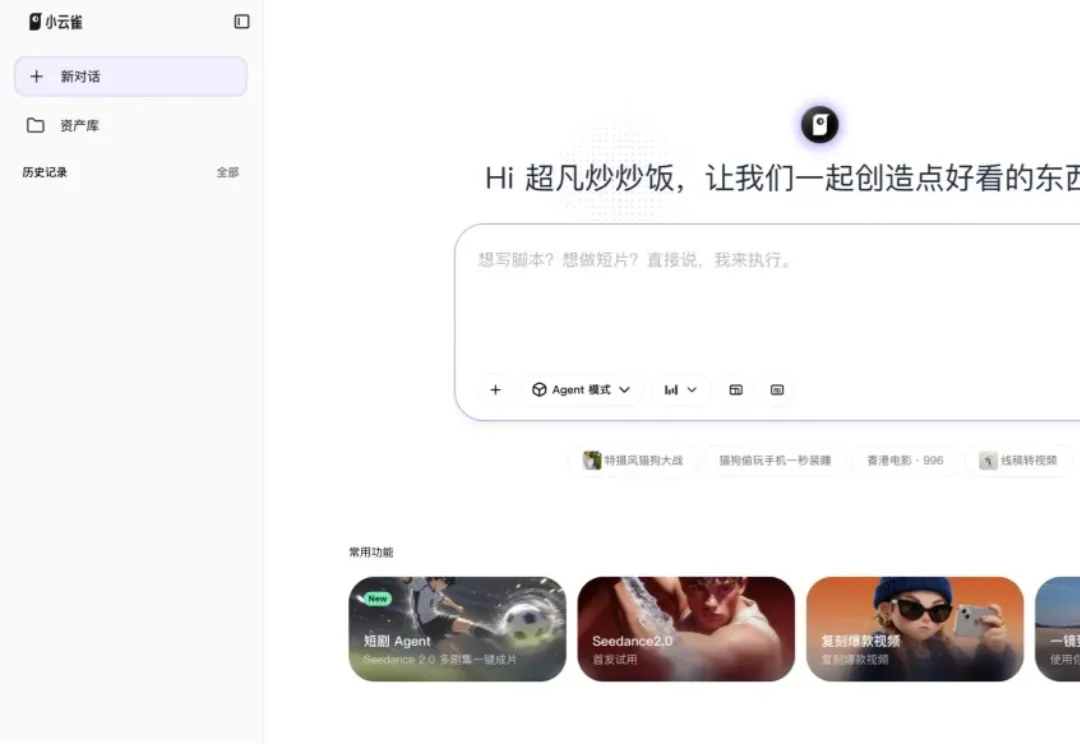
3 月 17 日,亚布力论坛年会现场,宇树科技创始人王兴兴被问及中国 AI 进展时,点名表扬了一款国产 AI:「今年一月份字节跳动 Seedance 2.0 视频生成软件,我觉得是全球目前最好的,全球遥遥领先。」
就在刚刚,世界第一个用Seedance 2.0做底层模型的AI短剧Agent,正式上线了。

人类创作者与 Agent 是平等的。
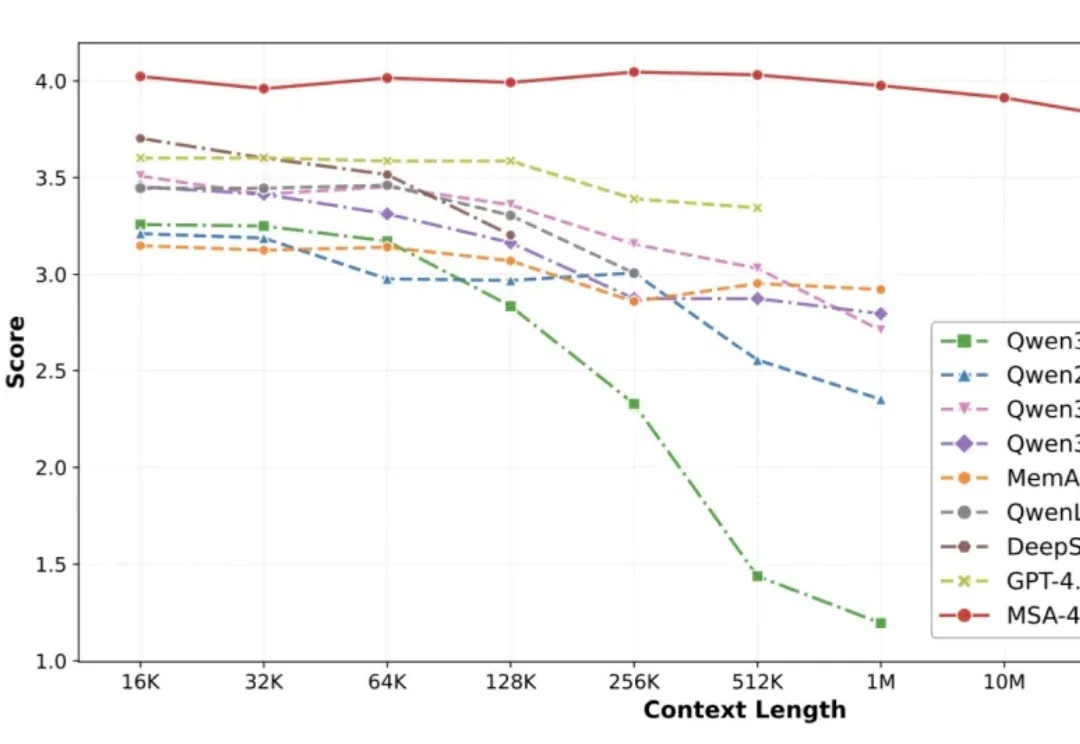
人的智能能力主要由推理能力和长期记忆能力构成。近年来,大模型的推理能力一直处于快速发展过程,但大模型的长期记忆能力一直受限于上下文长度,无法取得突破。在历史上,曾经有多种路线进行尝试,但都无法突破扩展性(Scalability)、精度(Precision)和效率(Efficiency)的不可能三角。

MLRA通过拆分KV缓存为四个并行分支,显著降低显存占用并实现4路张量并行。推理速度比MLA最高快2.8倍,支持百万级上下文,且模型质量更优。无需牺牲性能,即可高效扩展长文本处理能力。

谷歌DeepMind刚刚为Gemini API放了一个大招:内置工具和自定义函数终于可以在同一次调用里混着用了。再加上跨工具的「上下文环流」和Google Maps原生接入,Agent开发的编排噩梦正在终结。

OpenAI 发起全新挑战:你,准备好迎战了吗?

理想智驾“黄金一代”集体转向具身智能赛道。
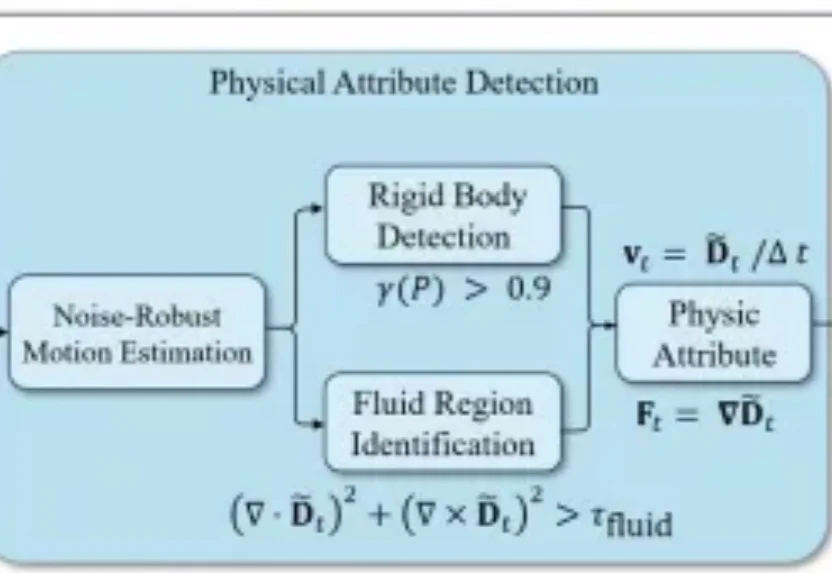
本文是北京大学彭宇新教授团队在文本生成视频领域的最新研究成果,相关论文已被 CVPR 2026 接收。

上周,除了 OpenClaw,AI 圈还有个词越来越火🔥。
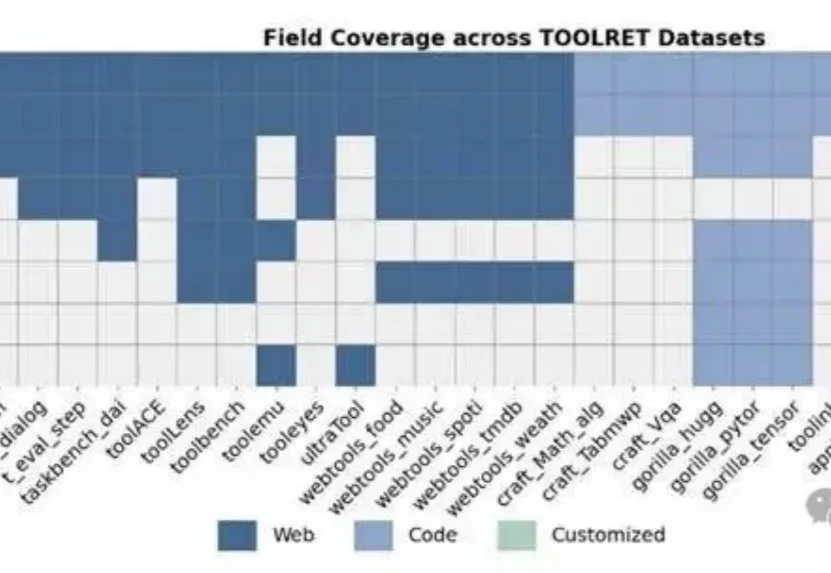
在大模型时代,Tool-Use已经成为智能体能力的核心组成部分。
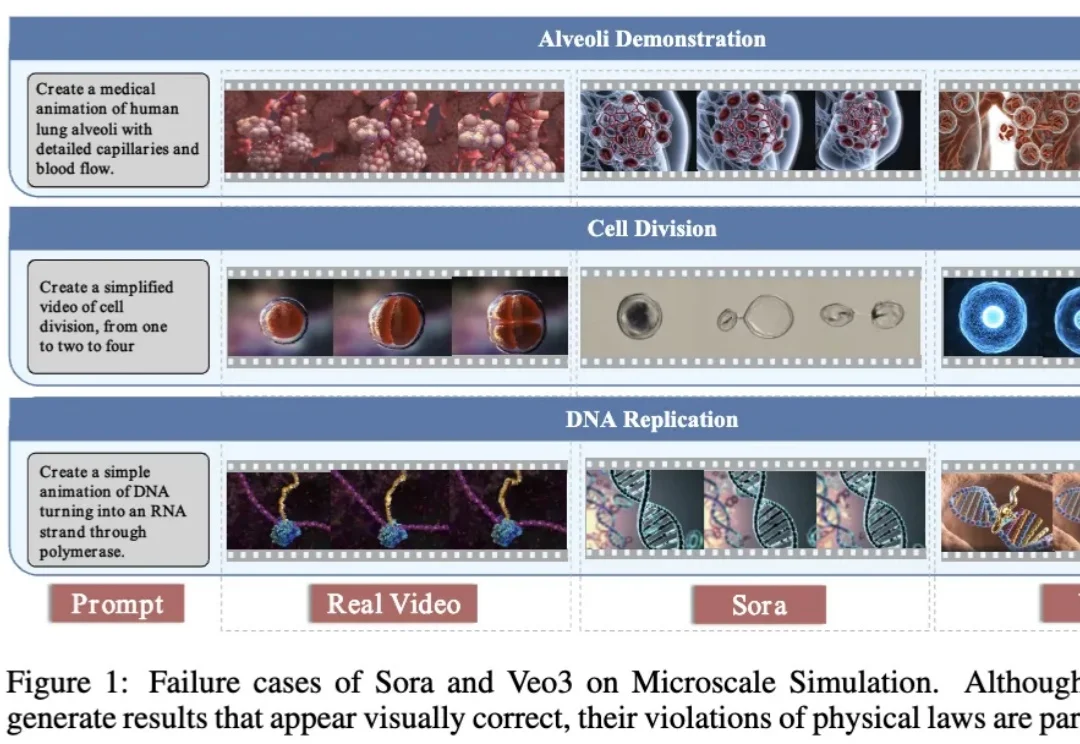
过去两年,世界模型(World Model)正在成为大模型演进的重要方向。
来自天工AI的SkyReels-V4,没打招呼,直接登顶Artificial Analysis文转视频(含音频)全球榜,超越Veo 3.1、Sora 2。一个月前,其Preview版本才刚拿下该榜全球第2。
我们需要的是一个 AI 工具,还是一个 AI 同事?

占领OpenRouter调用量榜单第一的神秘模型Hunter Alpha,终于揭开神秘面纱—— 既不是GPT,也不是DeepSeek,而是来自小米的万亿旗舰模型MiMo-V2-Pro。

Anthropic发布Cowork新功能Dispatch,用手机即可远程指挥Mac上的Claude执行任务。MacStories实测成功率约50%,但AI Agent从「坐在电脑前用」到「随时随地遥控」的关键一步,已经迈出。

Agnes AI近日披露了一组新的业务数据:全球用户规模已突破700万,年度经常性收入(ARR)接近2000万美元,并于去年底完成千万美元级融资。据公司方面透露,Agnes目前正在推进新一轮融资,目标估值约2亿美元,以持续投入核心技术研发并推动全球市场扩展。
谁能料到,OpenClaw 的热度从年初延续到了今天。除了专业工程师,很多普通人也在 FOMO(错失恐惧)情绪驱动下,开始了对「养龙虾」的追捧。
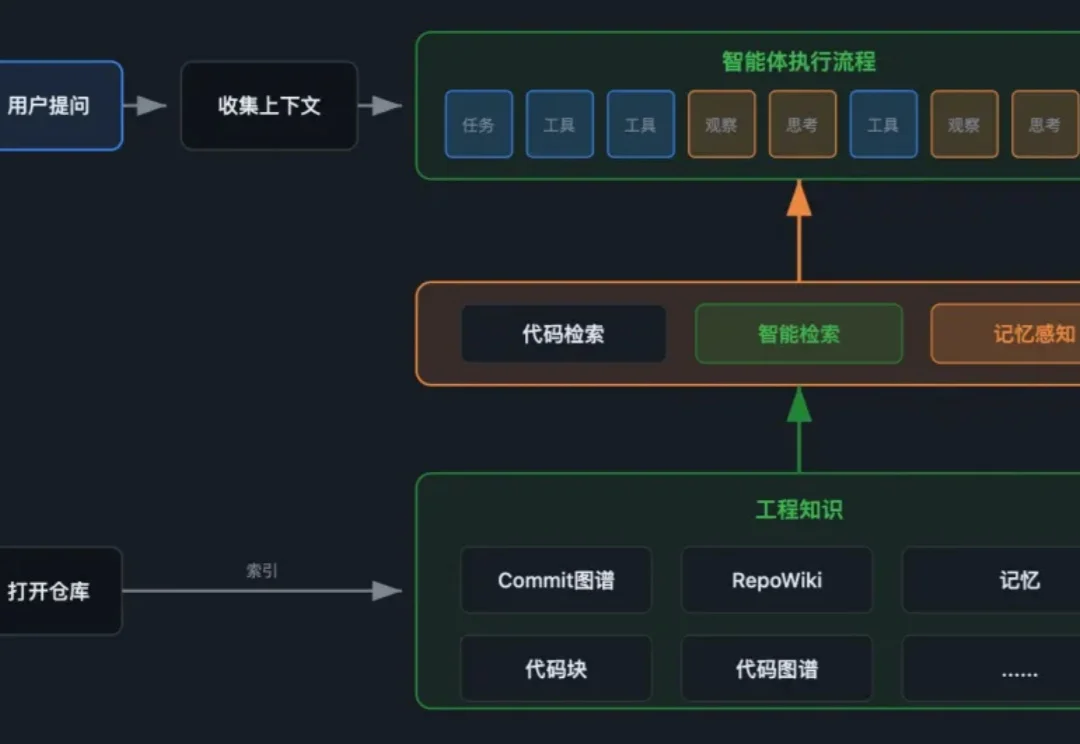
在AI编程智能体快速演进的今天,一个核心痛点愈发凸显:AI能写代码,却难以理解代码。更深层的问题是:即便模型能力再强,若缺乏结构化的工程约束与上下文支撑,智能体也难以稳定、可预期地完成真实工程任务。

EasyClaw+机器人会长成什么样子?这场活动让我们看到了雏形。

十亿参数单细胞基础模型scLong不再只看少数高表达基因,而是把一个细胞里接近 2.8 万个基因 都纳入建模,并结合 Gene Ontology(GO) 的生物学知识,去理解更完整的基因上下文。

如果你最近在关注AI Agent,可能已经被各种“能力展示”刷屏,从自动写代码到全流程办公自动化,几乎每一条都在强调效率与技术跃迁。
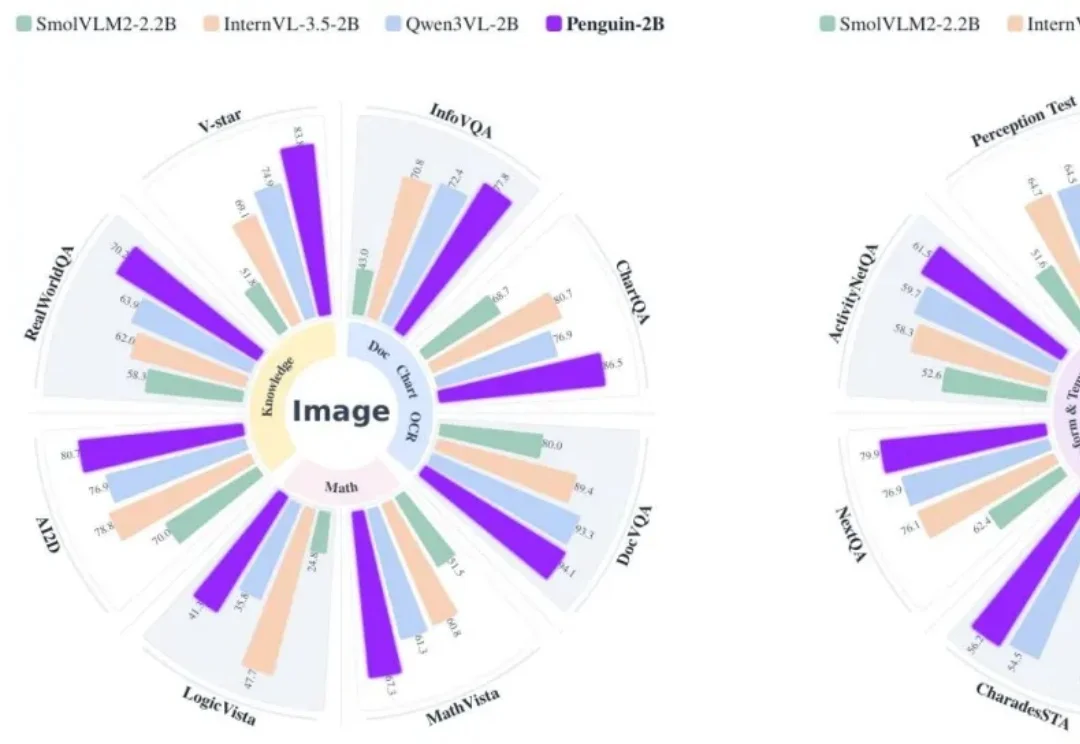
打破多模态视觉+语言拼接套路!

