

最近的AI信息焦虑,被阿里Agent团队治好了(附赠工具)
最近的AI信息焦虑,被阿里Agent团队治好了(附赠工具)大家好,我是袋鼠帝。 我用AI编程工具,花了半天时间开发出了这个,信息聚合与灵感管理平台(打破信息差),非常好用~
来自主题:
AI资讯
9816 点击 2026-03-23 14:10
 搜索
搜索
大家好,我是袋鼠帝。 我用AI编程工具,花了半天时间开发出了这个,信息聚合与灵感管理平台(打破信息差),非常好用~

随着 OpenAI 准备在下个月向更多营销人员开放广告销售,该公司正试图解决部分广告主反映的初期广告销售方案中存在的不足。除其他措施外,这家 ChatGPT 的创造者计划通过与广告技术公司合作或利用自有的广告管理系统,来简化广告购买流程。
事情果然和大家预想的一样!
养虾🦞(OpenClaw)这阵风刮得太猛了,不止个人在玩,企业也都在装,生怕落后。

“对具身智能来说,力觉比视觉更重要。”

4月21-22日北京站将正式举行~
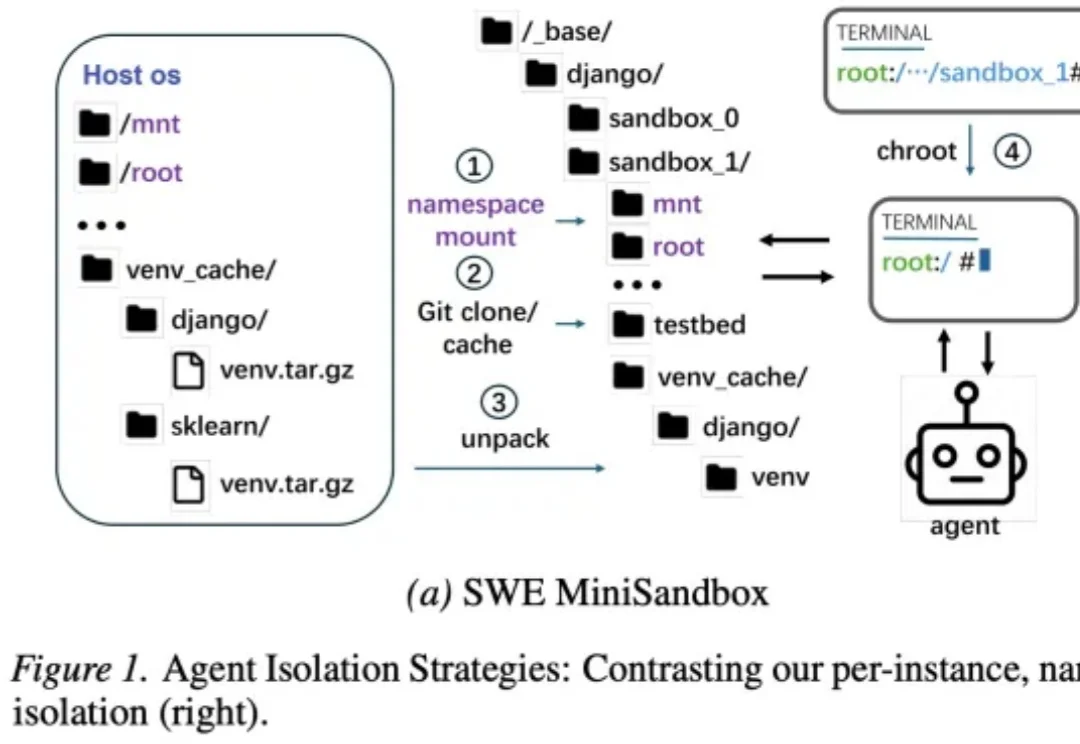
AI 编程这么火,想训练个 SWE Agent 却没有资源怎么办?

苦于AI单字拼凑没行气,或是排版秒变“鬼画符”?
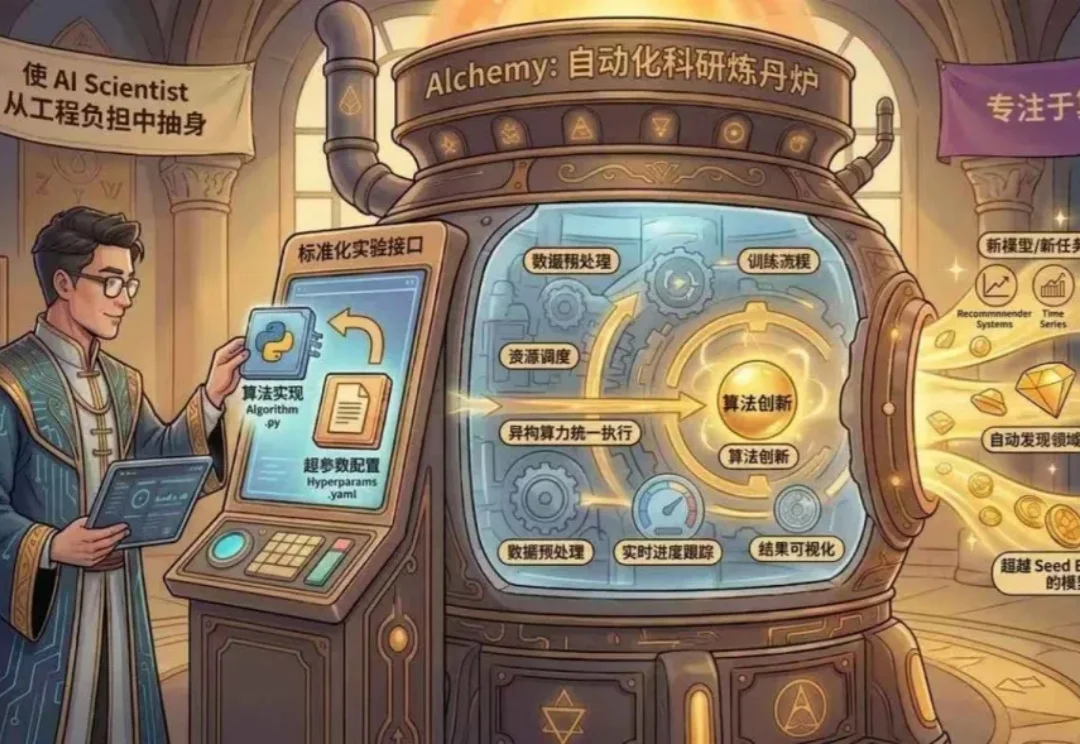
AI 驱动的自动化科研正从概念走向真实系统。近期受到广泛关注的 FARS,以及 Karpathy 开源的 autoresearch,都在不同程度上展示了 AI Scientist 自动进行 AI 领域研究的可行性。
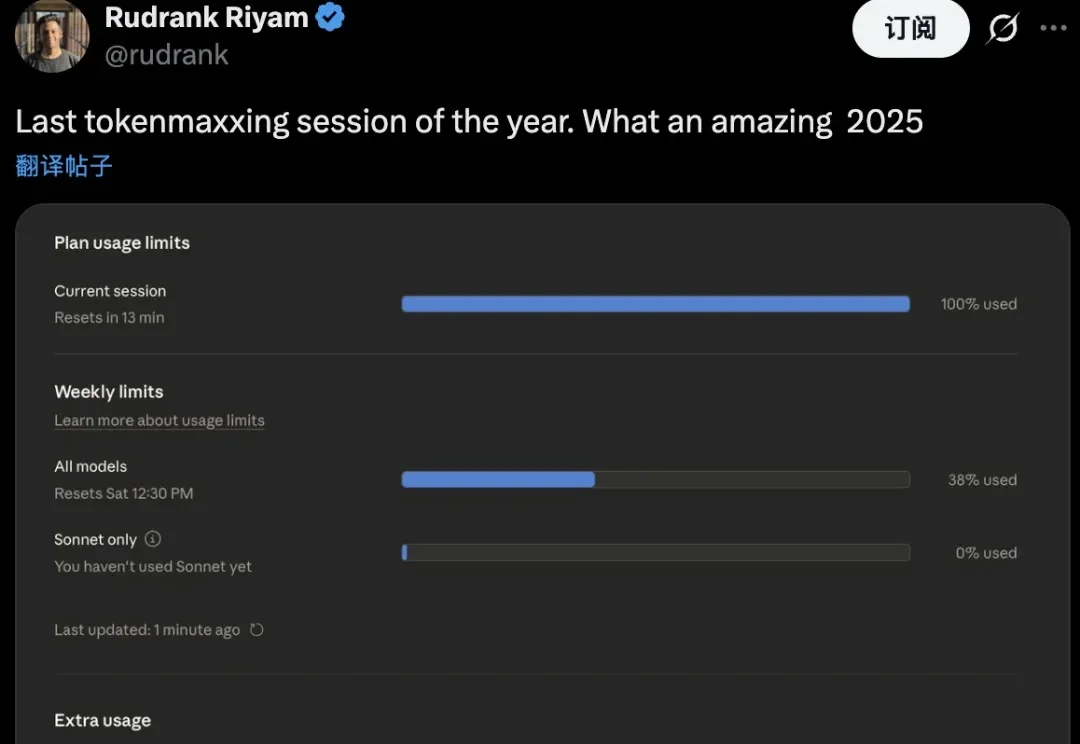
OpenAI最烧Token的人有多狠?

小时候看《冰雪奇缘》,相信有不少小孩问过父母:雪宝是真的吗?
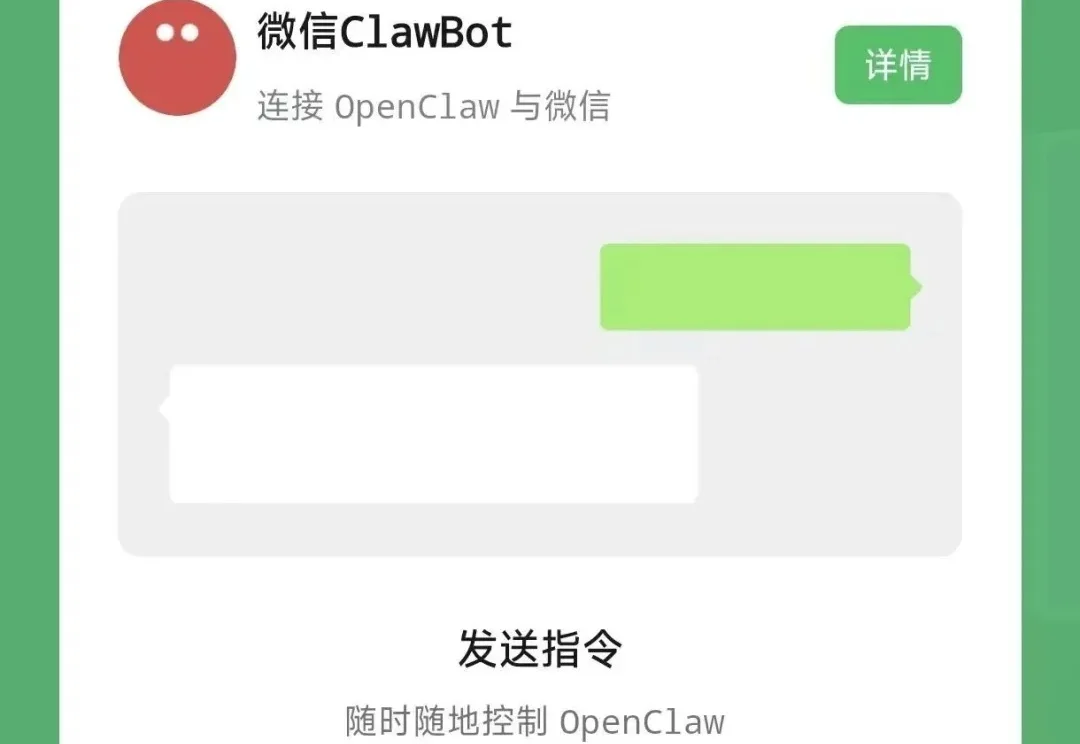
说实话,我看到微信官方开始支持 OpenClaw 的时候,第一反应不是震惊,而是感觉这事终于来了。
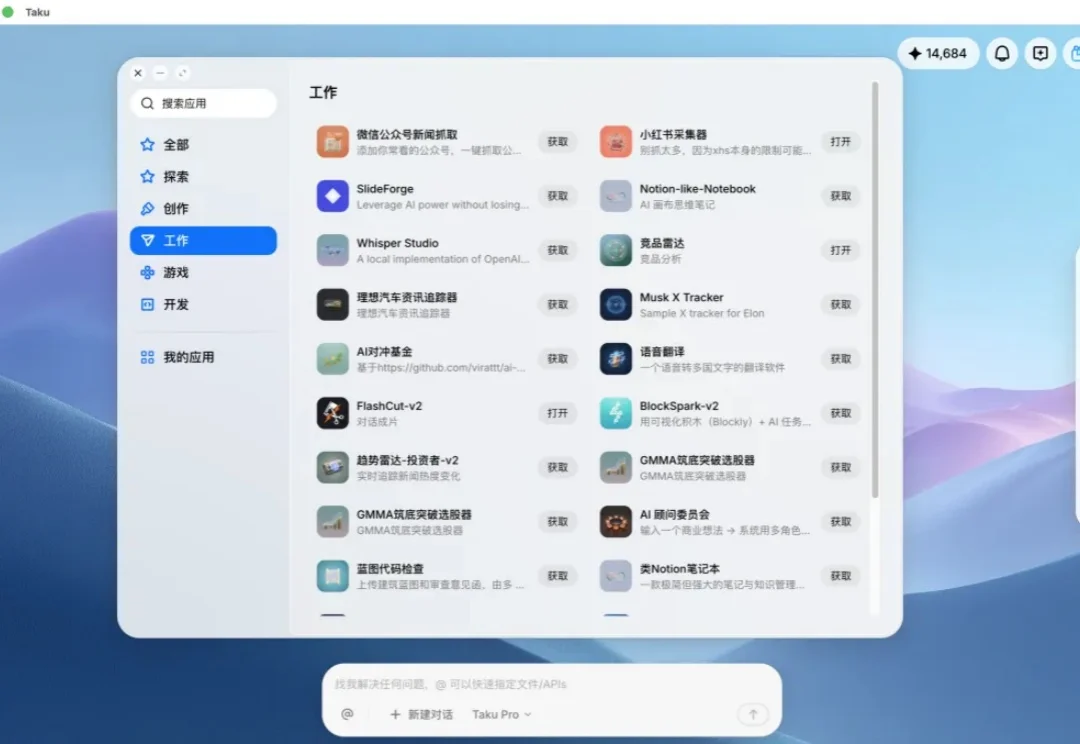
春节期间,注意到一个叫 Taku 的产品

DeepSeek,又有核心工程师流入江湖—— 郭达雅,V2、V3、R1等一系列模型的核心作者,被曝离职。

一个世纪诞生一万个爱因斯坦?APS全球物理学峰会上,哈佛物理学家放出豪言,「用AI增强人类,有望在世纪内催生10000个爱因斯坦」。

目标年产超过1万亿瓦算力。

GTC 2026,比往年更热。

Anthropic对80,508个真人做了一对一AI深度访谈——史上最大规模定性研究。人们最想要的不是更强的AI,而是更多的时间。但省下的时间去了哪里?这份报告的答案,比任何技术发布都让人不安。

在 AIGC 领域,基于参考图像的图像修复(Reference-based Inpainting)一直是一项备受关注的核心任务,它旨在利用参考图像引导修复过程,生成视觉一致的内容。这一技术在广告营销和电商领域有着巨大的应用潜力,例如让 AI 自动生成 “真人手持或穿戴商品” 的展示图。

一张蓝锥嘴雀的图片,你能认出它是“鸟”,但能认出它是“鸟纲-雀形目-唐纳雀科-锥嘴雀属-蓝锥嘴雀”吗?

这两年,扩散语言模型(Diffusion LLM)一直是个很有讨论度的方向。

多模态大模型,到底有多“嘴硬”? 浙江大学联合阿里巴巴、香港城市大

一个不存在的金发女兵,用AI合成的脸骗了一百万直男,用爱国人设收割了无数钱包——而这场骗局,可能只是AI虚假身份入侵现实世界的开场白。

今日,微信「ClawBot」插件正式发布,支持接入OpenClaw(昵称“龙虾”)。连接后,用户就能在微信聊天中与OpenClaw收发消息,指挥“龙虾”干活,用于个人学习、工作问题、内容创作等场景。
2026 年,OpenClaw 引爆 AI 圈,但 B 站 UP 主开发的硬核 Agent 框架 AstrBot 早在 2023 年 1 月就发布了第一个版本。B 站是如何凭借独特的社区反馈机制,成为孕育 AI 技术落地的「第一现场」?

一边的人,每次跟 Agent 说话都像重新 onboarding:得再讲一遍背景、偏好和上下文。另一边的人,Agent 已经知道自己是谁、该怎么说话、用户讨厌什么,也记得上次积累下来的东西。这条分界线,叫 workspace。

具身智能(Embodied AI)正从算法狂欢转向物理落地的「深水区」。在FLEXIVERSE 2026发布会上,非夕科技不仅通过Enlight、Orion、MICO等新品完成了从「单臂」到「通用机器人智能底座」的升维,更在现场达成了2000台机器人的战略合作签约。全身皮肤级力感知、720°超限旋转、双臂原生协同、无源吸附壁虎夹爪——
X 上到处都是各种传奇故事:有人已经用它赚了超过 140 万美元,有人短期内迅速赚了几万美元。这个项目在国内曝光的比较少,但在海外各个社区已经成了现象级项目。这个项目叫:MiroFish。

近日,由光合组织发起的全国线下OpenClaw体验活动“龙虾局”正在各地掀起热潮。从成都到昆山到天津再到杭州,上千名开发者与AI技术爱好者携带电脑到场,享受免费安装服务并领取免费Token算力资源。

